Learn how to identify and verify ChatGPT's sources to ensure accurate and reliable information in your conversations.
With the growing use of generative AI tools like ChatGPT, understanding where the information provided by these models comes from has become essential for brands and SEO/GEO professionals. When a user gets an answer from ChatGPT, is it generated out of thin air? Is it based on press articles, Reddit posts, or Wikipedia entries? Or does it pull information directly from live web searches? In this article, we'll take a closer look at the main sources used by ChatGPT, how to identify them manually, and how to save time by using the Qwairy tool to track your presence across LLMs.
ChatGPT is OpenAI's large language model (LLM) and includes several versions, with the main ones being:
GPT-3
GPT-3.5
GPT-4
On the other hand, SearchGPT is a hybrid LLM.
Hybrid LLMs access the web in real time using techniques like RAG (Retrieval-Augmented Generation).
Thanks to a partnership with Microsoft, SearchGPT leverages Bing search results.
As of April 2025, SearchGPT announced it now handles nearly 1 billion searches per week.
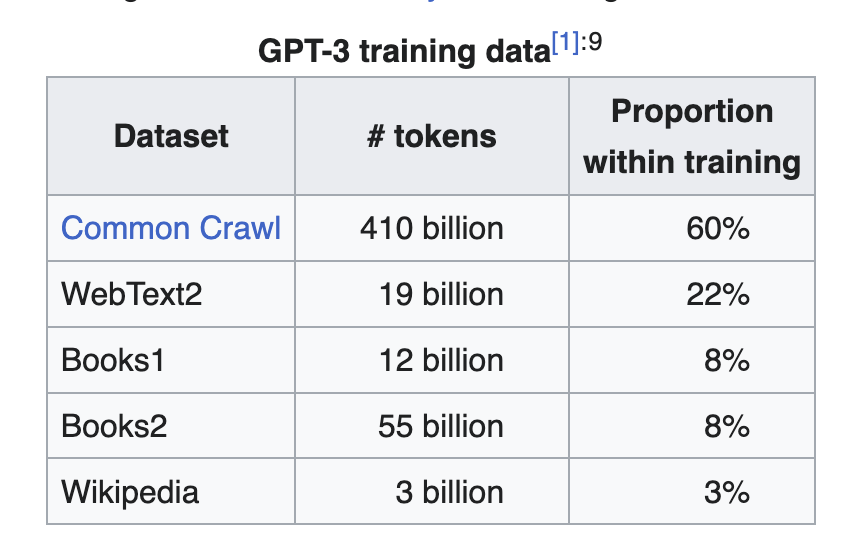
Every AI model is trained on a specific dataset, commonly referred to as a training corpus. The standard version of ChatGPT generates its answers based on a , which includes:
Other Articles
How to Set Up AI Referral Tracking in GA4, Plausible and Matomo
Most analytics tools miss or misclassify AI referral traffic by default. This step-by-step guide shows you how to properly track visits from ChatGPT, Perplexity, Claude, Gemini, and other AI platforms in GA4, Plausible, and Matomo.
How to Measure GEO ROI and Track AI revenue from LLMs (ChatGPT, Claude, Gemini…)
Every AI search dashboard shows citations. Almost none show revenue. This handbook gives you the three-layer framework, a maturity matrix, a 20-point audit, and the CFO conversation framework to fix that.
Wikipedia – widely used for general knowledge and factual information
Royalty-free books – from initiatives like Project Gutenberg
Open-access scientific papers – such as those from arXiv and PubMed
Public forums – including Reddit, Stack Overflow, and Quora
Open-source content – like GitHub repositories and technical documentation
Below is an overview of the training sources used for GPT-3:
Source: Wikipedia
 FYI Common Crawl is a non-profit organization that crawls the web and makes the data publicly available.
That said, LLM datasets evolve quickly. In France, for example, a partnership was signed between several media outlets - including lemonde.fr - and ChatGPT. As a result, lemonde.fr is now a regular source for SearchGPT.
Let's dive into that now.
FYI Common Crawl is a non-profit organization that crawls the web and makes the data publicly available.
That said, LLM datasets evolve quickly. In France, for example, a partnership was signed between several media outlets - including lemonde.fr - and ChatGPT. As a result, lemonde.fr is now a regular source for SearchGPT.
Let's dive into that now.
Since 2024, OpenAI has been signing numerous licensing agreements to use content from a wide range of media outlets and websites. To save you time, here's a list of publishers that have partnered with OpenAI:
Le Monde (France): First French media to sign an agreement with OpenAI. The partnership gives ChatGPT access to Le Monde articles to improve the reliability of its responses, with direct links to the sources cited.
News Corp (United States, United Kingdom, Australia): Agreement with a potential value of $250 million, including publications such as The Wall Street Journal, The Times, The Sun and The New York Post.
The Washington Post (United States): Strategic partnership enabling ChatGPT to provide summaries, quotes and direct links to original Washington Post articles.
The Financial Times (UK): Partner in OpenAI's "Preferred Publisher" program, offering increased visibility in ChatGPT.
Axel Springer (Germany): Agreement covering titles such as Bild, Die Welt and Politico Europe.
Prisa Media (Spain): Partnership with publications such as El País, Cinco Días and El HuffPost.
The Atlantic and Vox Media (United States): Licensing agreements for the use of their content in OpenAI products.
Associated Press (United States): License agreement signed in July 2023, allowing use of its archives for training AI models.
Reddit: Partnership signed in May 2024, offering OpenAI real-time access to Reddit content via its API. In return, Reddit benefits from AI-powered features and an advertising partnership with OpenAI.
Stack Overflow: Agreement allowing OpenAI to use Stack Overflow data to improve its AI models, while providing Stack Overflow with AI-based tools for its users.
SearchGPT: Prototype launched in July 2024, integrating partner press sources such as Le Monde, The Atlantic, News Corp, Prisa Media and Axel Springer to provide up-to-date answers with links to the original articles.
When the SearchGPT feature is enabled, the model can perform live searches via Bing to:
Retrieve up-to-date information (e.g., news, recent data)
Cite sources directly from Bing search results
This approach is known as RAG, or Retrieval-Augmented Generation.
Retrieval-Augmented Generation (RAG) is an AI technique that enhances response accuracy by retrieving relevant documents from a knowledge base and incorporating them into the generated output. It allows the model to ground its answers in real, external content.
🔎 Reminder: In this case, ChatGPT can display quotes with direct links to sources.
ChatGPT also uses other ways to get information:
Structured databases such as Wikidata.
Synthetic data created by OpenAI to refine models. OpenAI also reuses data from people who use its tool.
Run a free audit: see if ChatGPT, Gemini and Copilot recommend you, in about a minute.
When using ChatGPT, here's how to do it:
Ask a question.
Look for notes or quotes at the bottom of the answer.
You can also ask directly: "What are your sources for this answer?"
⚠️ Warning: sometimes ChatGPT will mention "I base my answer on my internal knowledge" if no web research has been done.
In SearchGPT, citations are much more visible. Links typically come from the top results on Bing. However, the pages shown in Bing search results don't always match exactly what ChatGPT references. Based on multiple tests we've run, it appears that ChatGPT relies on Bing SERPs from several weeks earlier rather than real-time results.
Tip: if you want to understand how ChatGPT might answer a query, do the same search on Bing and analyze the first articles.
Since Bing feeds SearchGPT, analyzing the Bing SERP allows you to anticipate which pages might be picked up.
No total transparency: except for displayed quotations, it's impossible to know with certainty the source of a piece of information.
Stochastic answers: the same question may give different answers.
Irregular updates: ChatGPT's database is only updated during new training sessions.
🔹 To sustainably influence an LLM, you need to play on the notoriety and authority of your content.
Qwairy is a SaaS solution that allows you to monitor:
Your brand's visibility across ChatGPT, Perplexity, Gemini, Claude, and other LLMs
The queries where your brand is mentioned on LLMs
The sources used by LLMs to generate responses
In practical terms, Qwairy analyzes the answers provided by LLMs to thousands of targeted questions and generates:
A dashboard showing whether and where your brand is mentioned
A source report listing the websites cited by the language models
A competitive analysis to see who's outperforming you
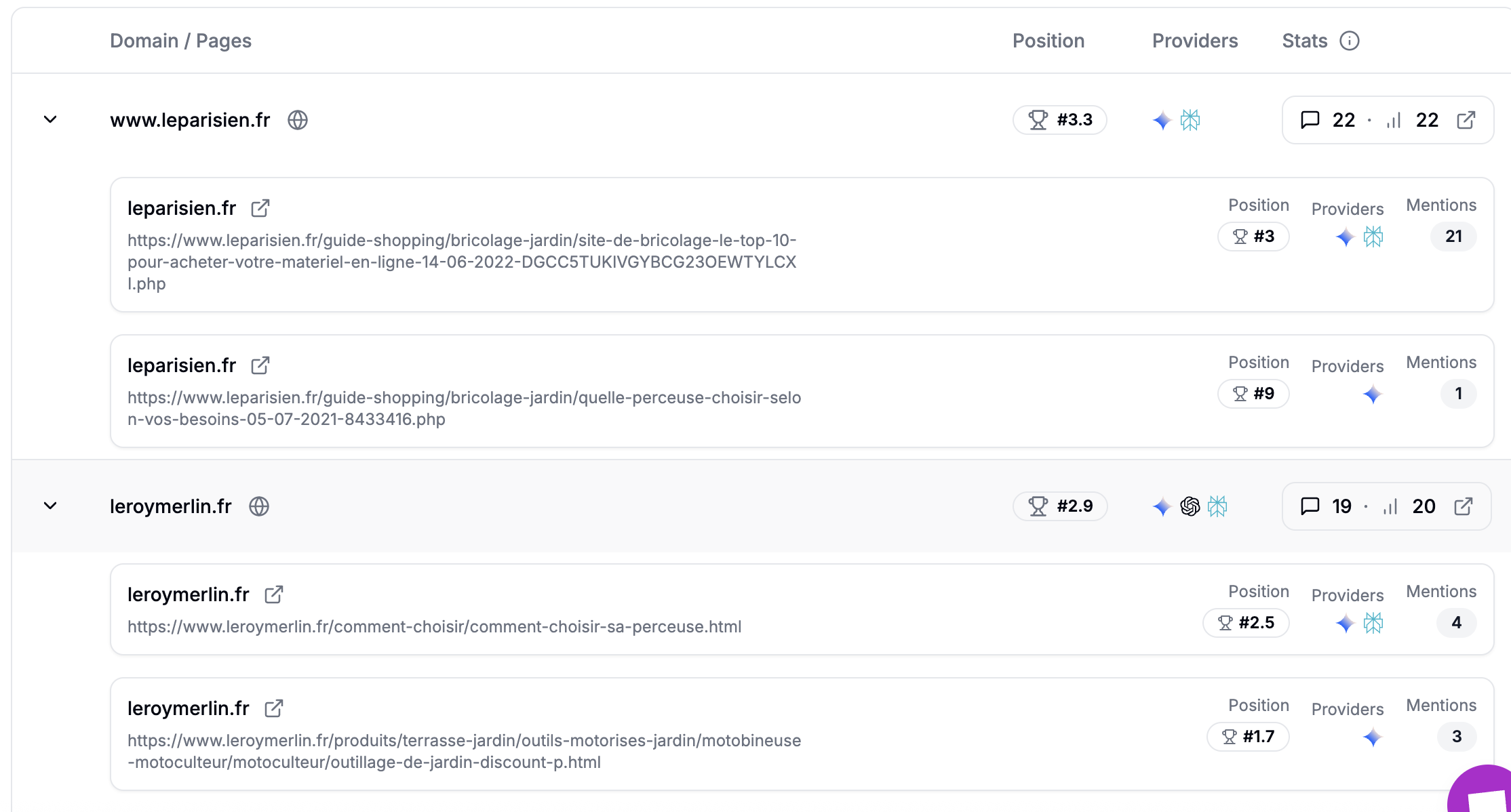
Qwairy gives you direct access to all the sources used by each LLM:
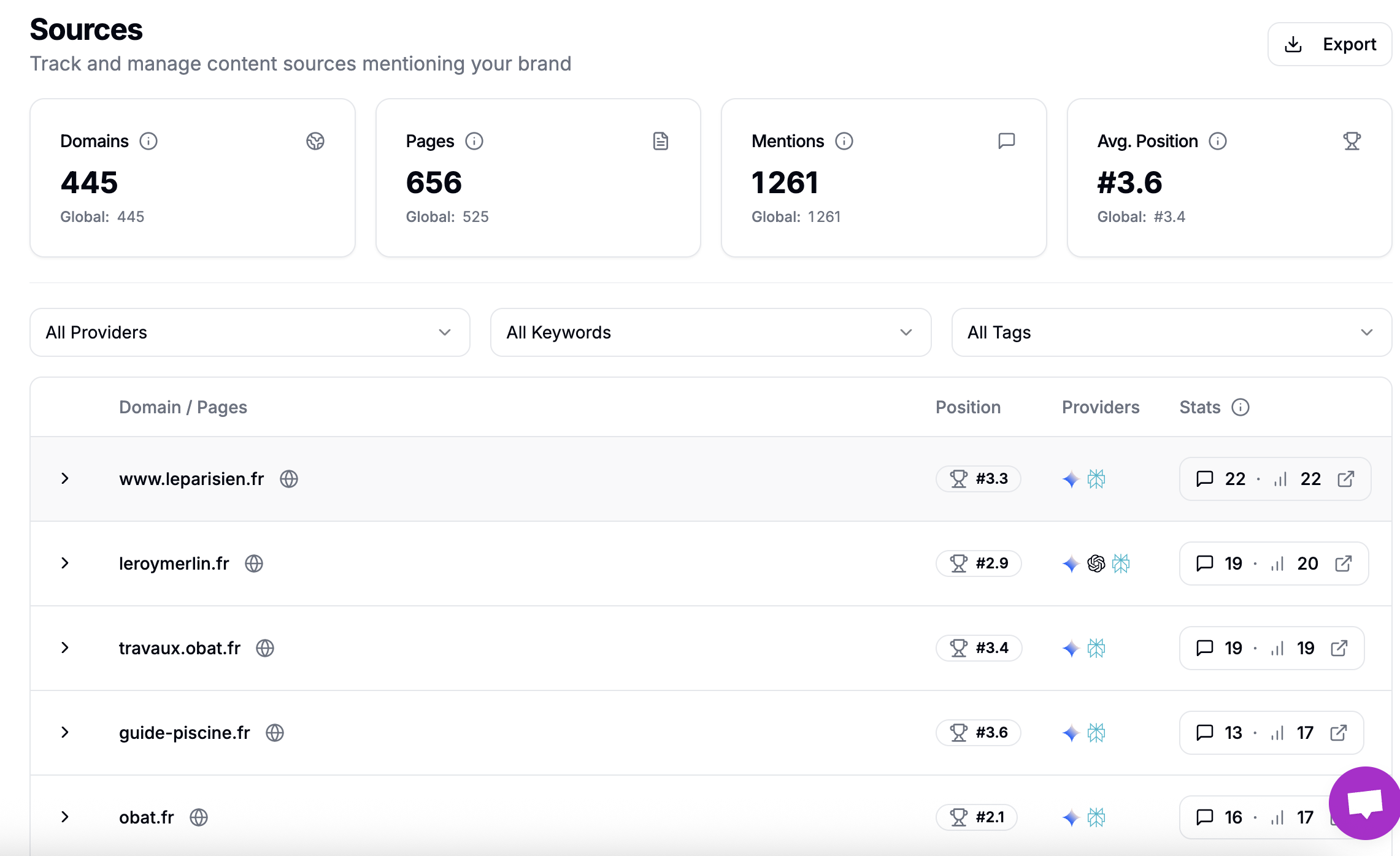 You can even see in detail which pages are cited:
You can even see in detail which pages are cited:
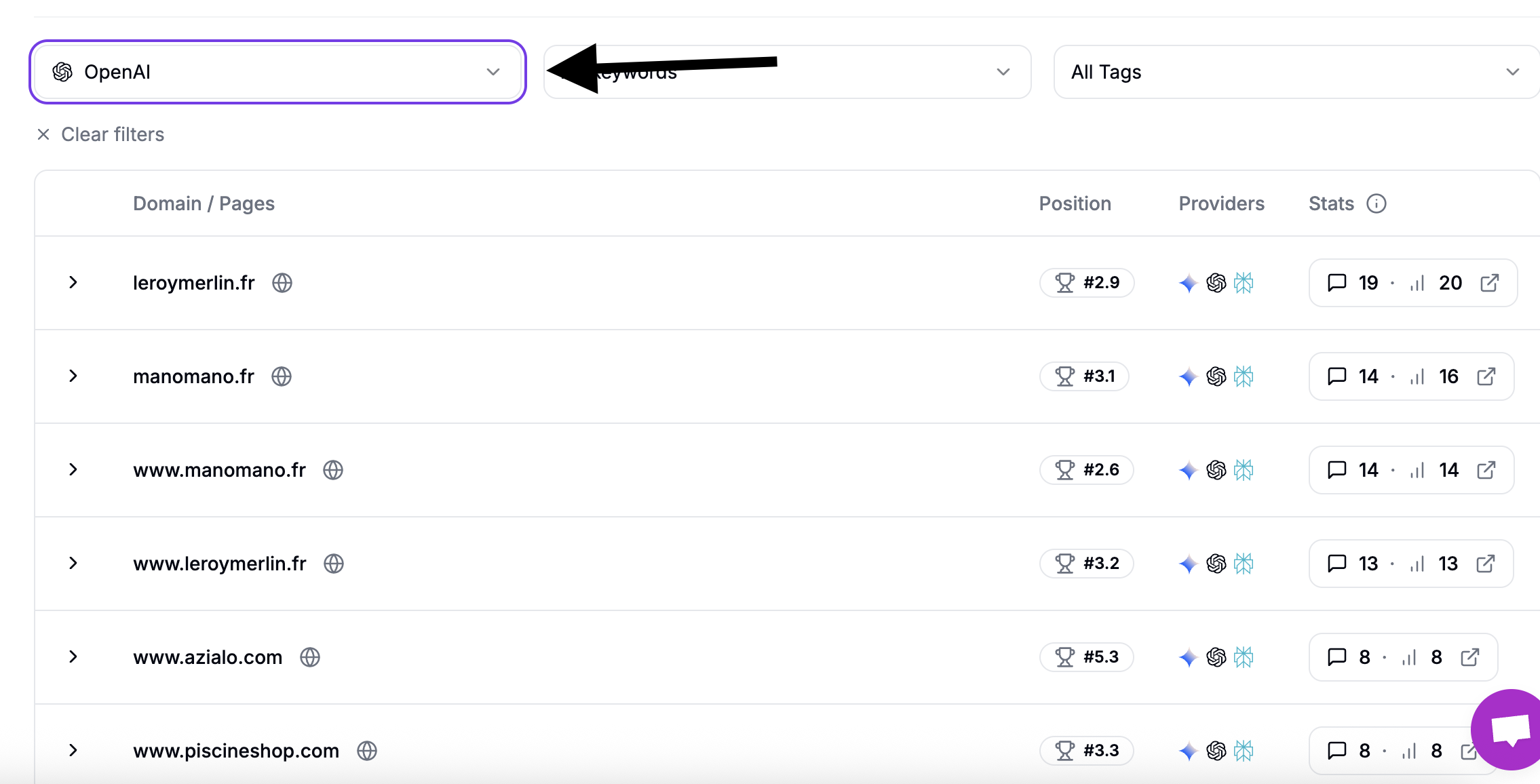
 And select the LLM you prefer to find out its sources (here we select ChatGPT):
And select the LLM you prefer to find out its sources (here we select ChatGPT):
The world of SEO is evolving towards a world where GEO (Generative Engine Optimization) is taking on a predominant role. Knowing which sources ChatGPT uses for its answers has become a key skill for:
Improving your content strategy.
Develop brand awareness.
Optimize backlinks in a targeted way.
✅ By combining intelligent manual monitoring with powerful tools like Qwairy, you'll be able to regain control over your visibility in LLMs and capture valuable traffic.
Ready to take action? Test your visibility on Qwairy and find out in just a few clicks where and how ChatGPT is talking about you.
ChatGPT's training corpus includes several key sources:
Wikipedia: General knowledge and factual information
Royalty-free books: From Project Gutenberg and similar initiatives
Open-access scientific papers: From arXiv, PubMed, and other academic sources
Public forums: Reddit, Stack Overflow, Quora content
Open-source content: GitHub repositories and technical documentation
Licensed media content: Partner publications like Le Monde, News Corp, The Washington Post
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
You can identify sources through several methods:
Look for citations: Check for notes or quotes at the bottom of ChatGPT's answers
Ask directly: Request "What are your sources for this answer?"
Analyze SearchGPT: SearchGPT displays more visible citations with direct links
Check Bing results: Since SearchGPT uses Bing, analyze Bing SERPs for the same query
Monitor quotes: SearchGPT often includes direct quotes from source materials
The two systems use different source mechanisms:
ChatGPT Standard: Uses pre-trained datasets with knowledge cutoffs, drawing from its training corpus
SearchGPT: Uses RAG (Retrieval-Augmented Generation) to access real-time web content through Bing search results
Citation visibility: SearchGPT provides direct links and visible citations, while standard ChatGPT rarely shows sources
Update frequency: SearchGPT accesses current information, while ChatGPT Standard relies on training data
OpenAI has established partnerships with numerous media organizations:
Le Monde (France): First French media partner
News Corp: Wall Street Journal, The Times, The Sun, New York Post
The Washington Post: Strategic partnership for summaries and direct links
Financial Times: Preferred Publisher program participant
Axel Springer: Bild, Die Welt, Politico Europe
Reddit and Stack Overflow: API access for real-time content
Manual source identification has several limitations:
No total transparency: Impossible to know all sources except for displayed citations
Stochastic answers: Same question may produce different responses and sources
Irregular updates: ChatGPT's database only updates during new training sessions
Time-consuming process: Manual verification is slow and not scalable
Incomplete picture: Tools like Qwairy provide more comprehensive source analysis
Track your mentions across ChatGPT, Claude, Perplexity and all major AI platforms. Join 1,500+ brands monitoring their AI presence in real-time.
Free trial • No credit card required • Complete platform access