Analysis of 102,018 AI queries reveals the truth: query fan-out varies by provider. Perplexity: 70.5% single-query. ChatGPT: 32.7% single-query. This provider-specific behavior is the hidden factor determining who wins in AI search.
Query fan-out is when an AI system generates multiple search queries from a single user prompt. Instead of searching once, the AI "fans out" across several related queries to gather comprehensive information. This phenomenon is transforming GEO strategies.
Example: User asks "best project management tools" → AI searches for 5 different variations (best PM software 2025, top collaboration tools, PM tools comparison, etc.)
ChatGPT: 3.51 queries/prompt average (67.3% multi-query)
Perplexity: 2.24 queries/prompt average (70.5% single-query)
"List" keyword trigger: 49 queries average (13.9x multiplier)
Query stability: Perplexity 92.8% consistent vs ChatGPT 11%
Trend: Single-query rate declining (65% Oct → 41% Nov)
Bottom line: Each AI platform searches differently. Focus your GEO strategy on the platforms your audience actually uses.
Last month, we helped a SaaS company discover why they ranked #1 in Perplexity but were invisible in ChatGPT. The reason: Perplexity generated 1 search query for their topic. ChatGPT generated 8. They optimized for the average (3-4 queries). They should have optimized for the reality: . We decided to quantify this with real data.
Other Articles
How Qwairy Predicts the 2026 World Cup Winner
A Qwairy research study on how AI answer engines frame the 2026 World Cup winner, where they agree, where answers become volatile, and what marketers can learn from AI perception mapping.
The Answer Is Now an Opening: How AI Engines Turn One Question Into a Funnel (June 2026)
We measured how AI engines END their answers on the commercial questions brands compete on: how often the engine closes by offering to keep going ("If you want, I can narrow this down by budget, region, use case"). Measured across the major AI engines we monitor over a 90-day window.
The Discovery: We analyzed 102,018 search queries from 38,418 user prompts across multiple AI providers (Sept-Nov 2025). The results? AI search behavior isn't one thing. It's a spectrum:
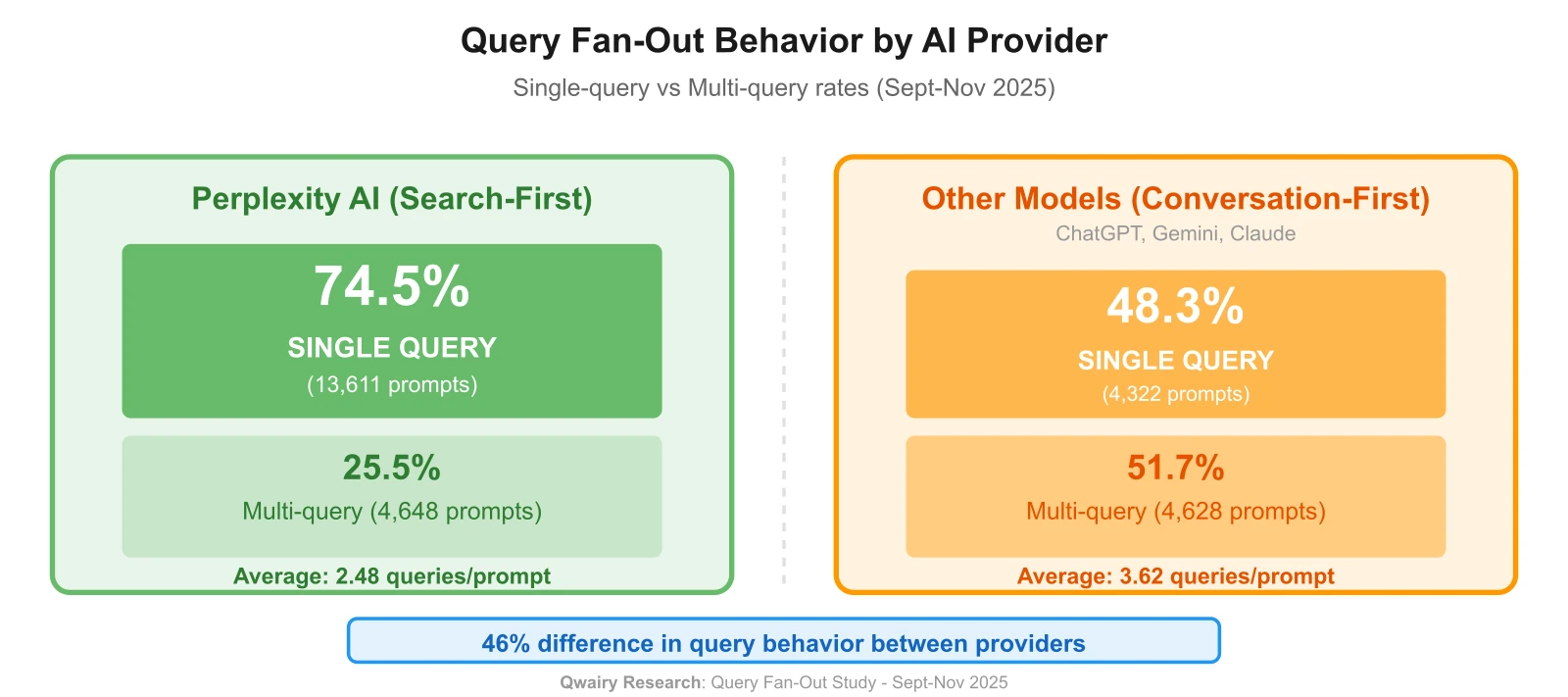
Perplexity** AI: 70.5% of prompts generate exactly ONE query**
ChatGPT: Only 32.7% generate exactly ONE query
That's a 2x difference in search behavior between providers. If you're optimizing for "average AI," you're leaving half your visibility on the table.
The Provider Split:
Perplexity: 70.5% single-query, 29.5% multi-query (avg: 2.24 queries/prompt)
ChatGPT: 32.7% single-query, 67.3% multi-query (avg: 3.51 queries/prompt)
Overall Average: 2.65 queries/prompt (true but hides massive provider variation)
Why It Matters: Multi-query prompts offer 5-10x visibility advantage, but only when providers actually fan out queries. Understanding which AI your audience uses changes everything.
The Two Laws:
What To Do: Know your audience's AI provider → Tailor optimization strategy → Track coverage by provider.
Dataset:
102,018 web search queries generated by AI systems
38,418 user prompts analyzed
Two providers tracked (Perplexity 67.2%, ChatGPT 32.8%)
Period: September-November 2025
Source: Qwairy Search Intelligence platform
What We Tracked:
Every search query AI systems generated in response to user prompts, then analyzed distribution patterns by provider, time, and query characteristics.
Before we dive in, full transparency:
What This Means: Provider-specific findings (e.g., "Perplexity is 70.5% single-query") are statistically robust. Overall statistics should be interpreted with sampling bias context.
Here's what we found when we split the data by AI provider:
Perplexity AI (67.2% of dataset):
Behavior | Prompts | Percentage |
1 query | 18,194 | 70.5% |
2+ queries | 7,604 | 29.5% |
Average | - | 2.24 queries/prompt |
ChatGPT (32.8% of dataset):
Behavior | Prompts | Percentage |
1 query | 4,133 | 32.7% |
2+ queries | 8,487 | 67.3% |
Average | - | 3.51 queries/prompt |
Perplexity (search-first):
Built to minimize queries and maximize precision
Only fans out when topic is genuinely ambiguous
Citation-focused: needs fewer queries when it finds quality sources
User expectation: Fast, precise answers
ChatGPT (conversation-first):
Built to explore and understand context
Fans out by default to gather multiple perspectives
Discovery-focused: explores solution space thoroughly
User expectation: Comprehensive, exploratory answers
The Strategic Implication: If your audience uses Perplexity: Win the single query. Be the #1 definitive source. If your audience uses ChatGPT: Win all query variations. Coverage = competitive advantage.
User prompt: "What are the best GDPR compliance agencies in France?"
Perplexity response: 1 query
GDPR compliance agency FranceChatGPT response: 6 queries
GDPR compliance agency France
GDPR consulting services Paris
data protection services France
GDPR agency France 2025
GDPR consultant enterprise
data protection expert France
Result: Brand appearing in all 6 ChatGPT queries gets 6x the visibility vs brand appearing in 1. But for Perplexity, coverage advantage doesn't exist. Only ranking matters.
We analyzed 38,418 prompts to understand what causes AI to fan out queries. The results reveal clear patterns that determine whether you get 1 query or 50+.
Keyword in Prompt | Avg Queries/Prompt | Multiplier vs Baseline |
"list/liste" | 49.01 | 13.9x |
"top" | 8.44 | 2.4x |
"comparison/vs" | 5.67 | 1.6x |
"best/meilleur" |
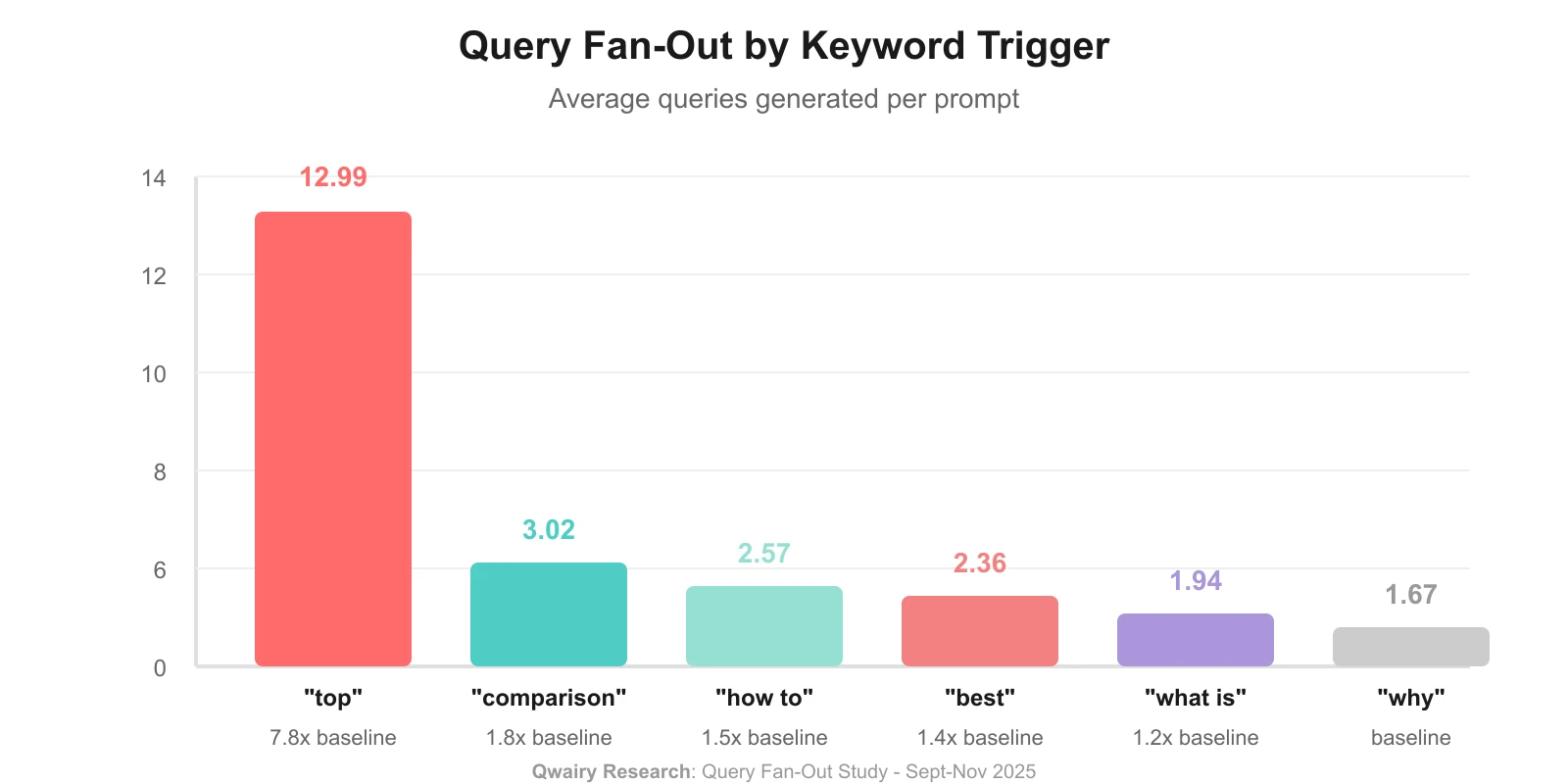
Key Finding: Prompts with "list/liste" generate 14x more queries than factual questions. "Top" prompts generate 2.4x more.
Why This Matters:
Recommendation-seeking queries = high fan-out = multiplier effect kicks in
Factual queries = low fan-out = ranking matters more than coverage
Strategic Implication: If your content targets "top X" or "best Y" queries, you're competing in a high fan-out environment where coverage advantage is real. Optimize for all query variations. Learn how to identify prompts that trigger this behavior.
Run a free audit: see if ChatGPT, Gemini and Copilot recommend you, in about a minute.
Prompt Length | Avg Queries/Prompt | Sample Size |
Short (\<50 chars) | 9.31 | 1,947 prompts |
Medium (50-100) | 3.10 | 23,644 prompts |
Long (100-200) | 3.27 | 3,228 prompts |
Very Long (200+) | 4.07 |
Counterintuitive Discovery: Short prompts generate 3x more queries than medium-length prompts.
Why? Short prompts are often:
List-seeking ("top 10...")
Ambiguous (AI needs to explore)
Recommendation-heavy ("best...")
Longer prompts are more specific, giving AI clear direction = fewer queries needed.
High fan-out patterns (1,000+ queries): Competitive B2B service queries in local markets consistently generate extreme fan-out:
"Top 10" listicle queries
Agency/consultant recommendations
Tool comparisons
Location-specific service searches
Low fan-out patterns (single query): Informational, non-commercial, specific questions typically result in a single targeted query:
"Why" explanatory questions
Specific factual lookups
Non-commercial curiosity queries
High Fan-Out Topics (top, best, agencies, tools):
✓ Invest in comprehensive coverage
✓ Create content clusters for all semantic variations
✓ Schema markup critical (help AI understand relationships)
✓ Track coverage % (missing 1 variation = 20% visibility loss)
✓ Use GEO tools to monitor performance
Low Fan-Out Topics (why, what is, specific facts):
✓ Focus on ranking #1 for the single query
✓ Be the definitive source
✓ Don't over-invest in variations (marginal returns)
We analyzed 102,018 generated queries to reveal how AI rewrites user prompts. Three patterns change everything:
AI adds "2025" to 28.1% of queries even when users don't mention it. The ratio is extreme: 2025 appears 184x more than 2024.
What AI Does:
User: "best project management tools"
AI searches: "best project management tools 2025"
Why: Architectural recency bias confirmed by Waseda University (2025): 65-89% of AI citations favor 2023-2025 content.
Action: Add current year to titles, H1s, and first paragraph. If your content says "2024" or has no year, you're invisible.
Real example:
User: "Je cherche une assistance juridique dédiée aux droits des travailleurs"
AI generates: assistance juridique droits travailleurs + ...France + ...Paris
AI adds evaluative keywords too: "meilleur" appears in 16.7% of queries, "best" in 5.9%.
Most auto-added keywords:
Geographic: "France" (13.9%), "Paris" (5.1%)
Evaluative: "meilleur" (16.7%), "best" (5.9%), "top" (4.6%)
Trust signals: "reviews/avis" (4.0%), "comparatif" (1.8%)
Strategy: Optimize for intent-implied keywords (best, top, local) even if users don't type them.
Critical discovery: Query stability is provider-dependent, not universal. We analyzed 13,610 questions asked multiple times across 2.1M+ pairwise comparisons:
Perplexity is deterministic: Same prompt → same query 93% of the time. The search-first architecture generates consistent, targeted queries.
ChatGPT is non-deterministic: Same prompt → different queries 89% of the time. The conversation-first architecture explores different angles each run.
Why This Matters: The strategic implications are opposite depending on your audience's AI:
For Perplexity users:
Query stability means ranking consistency
Win the single query = sustained visibility
Less need for extensive semantic coverage
For ChatGPT users:
Query instability means unpredictable visibility
Semantic coverage is critical (you can't predict which variation will be asked)
Traditional keyword targeting becomes less reliable
Strategy Shift: Know your audience's AI preference. For ChatGPT-heavy audiences, cover all semantic variations. For Perplexity-heavy audiences, focus on ranking #1 for the primary query.
Finding: Query behavior varies by 2x+ depending on AI provider
What This Means for You:
Perplexity Optimization:
✓ Rank #1 for the core query
✓ Citation-worthy content (data, research, original stats)
✓ Structured content (tables, lists that are easy to parse)
✓ Fresh content (updated regularly with current year)
✗ Don't obsess over query variations (matters less)
ChatGPT Optimization:
✓ 100% coverage across all semantic variations
✓ Content clusters (pillar page + supporting pages)
✓ Optimize for different intents (info, comparison, commercial)
✓ Schema markup (help AI understand relationships)
✓ Multi-angle content (different ways to answer same question)
Academic Confirmation: The ArXiv paper "Towards AI Search Paradigm" (2024) confirms that different AI architectures "dynamically adapt to the full spectrum of information needs" with fundamentally distinct search strategies.
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
Finding: Appear in all query variations = 5-10x visibility advantage (for multi-query providers)
The Math:
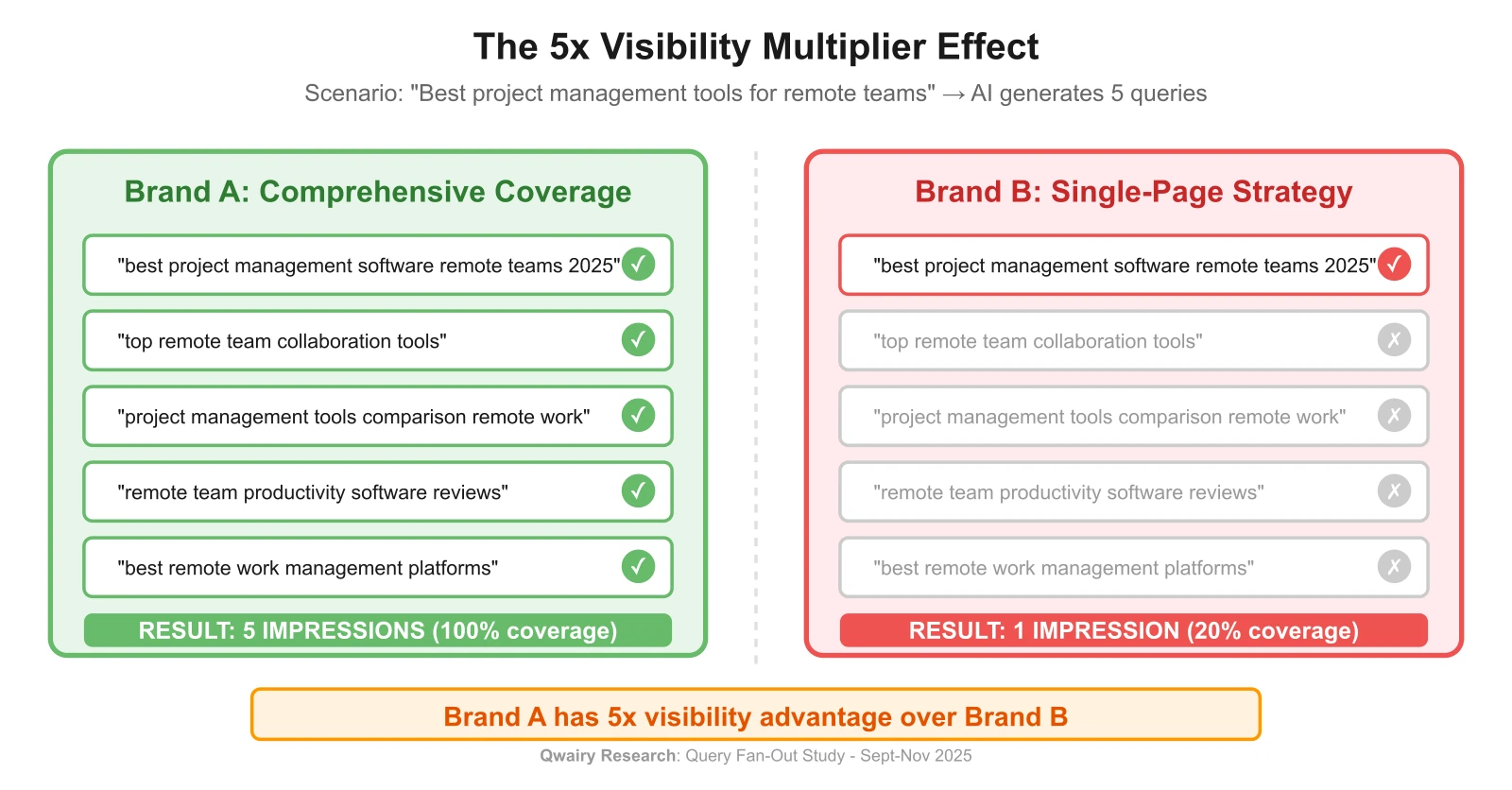
Scenario: "Best project management tools for remote teams"
AI Generates 5 queries:
best project management software remote teams 2025top remote team collaboration toolsproject management tools comparison remote workremote team productivity software reviewsbest remote work management platformsBrand A (comprehensive coverage): Appears in all 5 → 5 impressions
Brand B (single-page strategy): Appears in 1 → 1 impression
Result: Brand A has 5x visibility advantage
Key Insight: Missing even 1 query variation means losing 20% of potential visibility. The math is simple: if ChatGPT generates 5 queries and you only appear in 4, you lose 20% of impressions.
Critical Caveat: This multiplier effect only applies to conversation-first providers like ChatGPT with 67.3% multi-query rate. For Perplexity (29.5% multi-query), coverage advantage is minimal.
How to Achieve 100% Coverage:
Language | Percentage |
French | 31.2% |
English | 13.7% |
Mixed/Other | 55.1% |
Insight: Our dataset reflects our French/European client base. Among clearly-detected languages, French queries dominate (31.2% vs 13.7% English). The high "Mixed/Other" category (55.1%) includes queries with minimal text or mixed-language content.
Implication: Language distribution varies by market. Track your actual query language distribution rather than assuming English dominance.
Wrong: "AI generates 3-4 queries, so I'll create 3-4 content pieces and call it a day."
Reality: Perplexity (2.24 avg) vs ChatGPT (3.51 avg) = 57% difference.
Right: Know which AI your audience uses. Tailor strategy to that provider's architecture.
Wrong: "I'll optimize the same way for all AI platforms."
Reality: Search-first (Perplexity) vs conversation-first (ChatGPT) = fundamentally different behaviors.
Right: Perplexity = rank #1. ChatGPT = comprehensive coverage.
Wrong: "I'll optimize for ChatGPT because it has the biggest market share."
Reality: If your B2B SaaS audience uses Perplexity heavily, your multi-query strategy is wasted effort.
Right: Analyze your AI referral traffic → optimize for your actual audience's preferred platform.
Query fan-out is when an AI generates multiple search queries from a single user prompt. Instead of one search, the AI "fans out" across related variations to gather comprehensive answers.
Based on our analysis of 102,018 queries: ChatGPT averages 3.51 searches per prompt, with 67.3% of prompts triggering multiple queries.
Yes, but less frequently. Perplexity generates 2.24 queries per prompt on average, with 70.5% of prompts resulting in a single query. Its search-first architecture prioritizes precision over exploration.
Certain keywords dramatically increase fan-out:
"List" triggers 49 queries on average (13.9x multiplier)
"Top" triggers 8.4 queries (2.4x multiplier)
"Best" triggers 3.7 queries (1.1x multiplier)
"What is" triggers 1.96 queries (minimal fan-out)
No. Our data shows single-query prompts declined from 65.4% (October) to 40.8% (November 2025). AI search is evolving toward more multi-query behavior.
Depends on your audience's AI:
Perplexity users: Focus on ranking #1 for the core query
ChatGPT users: Achieve 100% coverage across all semantic variations
Check your analytics to see which AI your audience uses
Query rewriting transforms a single prompt into a single optimized query. Query fan-out generates multiple queries from one prompt. Both happen, but fan-out creates the visibility multiplier effect.
Architecture. ChatGPT is conversation-first (explores multiple angles). Perplexity is search-first (minimizes queries for precision). Different tools, different behaviors.
If you've been optimizing for "average" AI behavior, you've been fighting with one hand tied behind your back. The brands winning in AI search understand one critical truth: AI search isn't one thing. It's a spectrum of behaviors determined by provider architecture. The question isn't "How do I rank in AI?" It's "Which AI am I optimizing for?" Because the answer changes your entire strategy:
Perplexity** users?** → Win the single query. Be definitive.
ChatGPT** users?** → Win all variations. Be comprehensive.
Both? → You need two strategies, not one. Track your brand mentions across both platforms.
The data is clear. The insights are actionable. The competitive advantage belongs to brands who understand that provider architecture determines search behavior.
What will you optimize for?
Conducted by: Luca Fancello & Nicolas Ilhe
Dataset: 102,018 queries from 38,418 prompts
Period: September-November 2025
Methodology: Quantitative analysis of AI-generated search queries across multiple providers with full transparency on sampling bias
Sampling Bias Disclosure:
Our dataset over-represents Perplexity (67% vs ~6-8% market share) due to client base
This affects overall averages but not provider-specific patterns
Provider-level findings (e.g., "Perplexity is 70.5% single-query") are statistically robust
Overall statistics presented with bias context
Outlier Sensitivity:
10% of prompts are statistical outliers (>50 queries)
Removing outliers changes mean by −21.3% but median stays stable
Our findings focus on median and percentages (robust to outliers)
This study is supported by external research:
Nectiv ChatGPT Search Study (October 2025, 8,500+ prompts)
Want to track your query fan-out coverage by provider? Qwairy monitors AI responses across Perplexity, ChatGPT, and other platforms, showing you exactly how each provider generates queries for your topics and where your coverage gaps are.
Track your mentions across ChatGPT, Claude, Perplexity and all major AI platforms. Join 1,500+ brands monitoring their AI presence in real-time.
Free trial • No credit card required • Complete platform access
1.1x |
"how to/comment" | 3.40 | 1.0x (baseline) |
"why/pourquoi" | 2.89 | 0.8x |
"what is/qu'est" | 1.96 | 0.6x |
30 prompts |
Provider | Pairwise Comparisons | Avg Query Overlap | Variation Rate |
Perplexity | 2,057,376 | 92.8% | 7.2% |
ChatGPT | 128,565 | 11.0% | 89.0% |
Provider | Single-Query Rate | Multi-Query Rate | Avg Queries/Prompt |
Perplexity | 70.5% | 29.5% | 2.24 |
ChatGPT | 32.7% | 67.3% | 3.51 |
Difference | -37.8pp | +37.8pp | +57% |