
The most comprehensive study ever conducted on LLM ranking factors, analyzing 184,128 queries and 1,479,145 sources across 20 AI models including ChatGPT, Gemini, Perplexity, Claude, Mistral, DeepSeek, and Grok to help you dominate AI-generated results.
Other Articles
How Qwairy Predicts the 2026 World Cup Winner
A Qwairy research study on how AI answer engines frame the 2026 World Cup winner, where they agree, where answers become volatile, and what marketers can learn from AI perception mapping.
The Answer Is Now an Opening: How AI Engines Turn One Question Into a Funnel (June 2026)
We measured how AI engines END their answers on the commercial questions brands compete on: how often the engine closes by offering to keep going ("If you want, I can narrow this down by budget, region, use case"). Measured across the major AI engines we monitor over a 90-day window.
When we published our first study on 32,961 queries (Q2 2025), the response was overwhelming. Marketers worldwide reached out asking for more data, more models, and more insights. Three months later, we're back with something 5.6x bigger.
We analyzed 184,128 queries - that's 459% more data than our original study - across the latest LLM models, including newly tracked Mistral, DeepSeek, Grok, and GPT-5. But this isn't just about scale. This study introduces revolutionary new analysis dimensions:
TOFU/MOFU/BOFU breakdown - discover why purchase-intent queries trigger 2.5x MORE competitor mentions
Competitor mention rate analysis - from DeepSeek's 100% to GPT-5's ultra-selective 19.23%
Brand position tracking - which models rank your brand in the top 3?
Source concentration metrics - Gini coefficients revealing which models favor diverse vs narrow sourcing
Commercial content preferences - why 77.6% of Perplexity citations are business sites
The AI search landscape is evolving faster than anyone predicted. Last weekend, I overheard a conversation at a café that perfectly captures this shift:
"Let me ask ChatGPT which restaurant to try." Not Google. ChatGPT. This is the new reality. Search is being reimagined, and brands that don't adapt will simply disappear from consumer consideration. At Qwairy, our mission is to give you the data you need to win in this new landscape through Generative Engine Optimization (GEO). This study represents 1,479,145 sources analyzed, 20 different LLM models tracked, 106% monthly growth rates, and countless hours of analysis to bring you actionable insights. If you're new to GEO, we recommend reading our complete guide to understanding AI crawlers and GEO vs SEO: What's the difference to get the full picture. Let's dive in.
All data was generated using Qwairy, our GEO (Generative Engine Optimization) platform designed to help brands improve their presence in LLM-generated responses. The dataset includes:
184,128 queries analyzed (up 459% from 32,961 in our original study)
1,479,145 sources identified (up 2,365% from 59,992!)
20 LLM models tracked, including new entrants like Mistral, DeepSeek, Grok, and GPT-5
Data collection period: July 27 - October 27, 2025 (3 months)
Temporal growth: 106% average month-over-month increase
Our analysis covers 20 different LLM models across 8 major AI platforms - the most comprehensive dataset ever assembled for an AI search study:
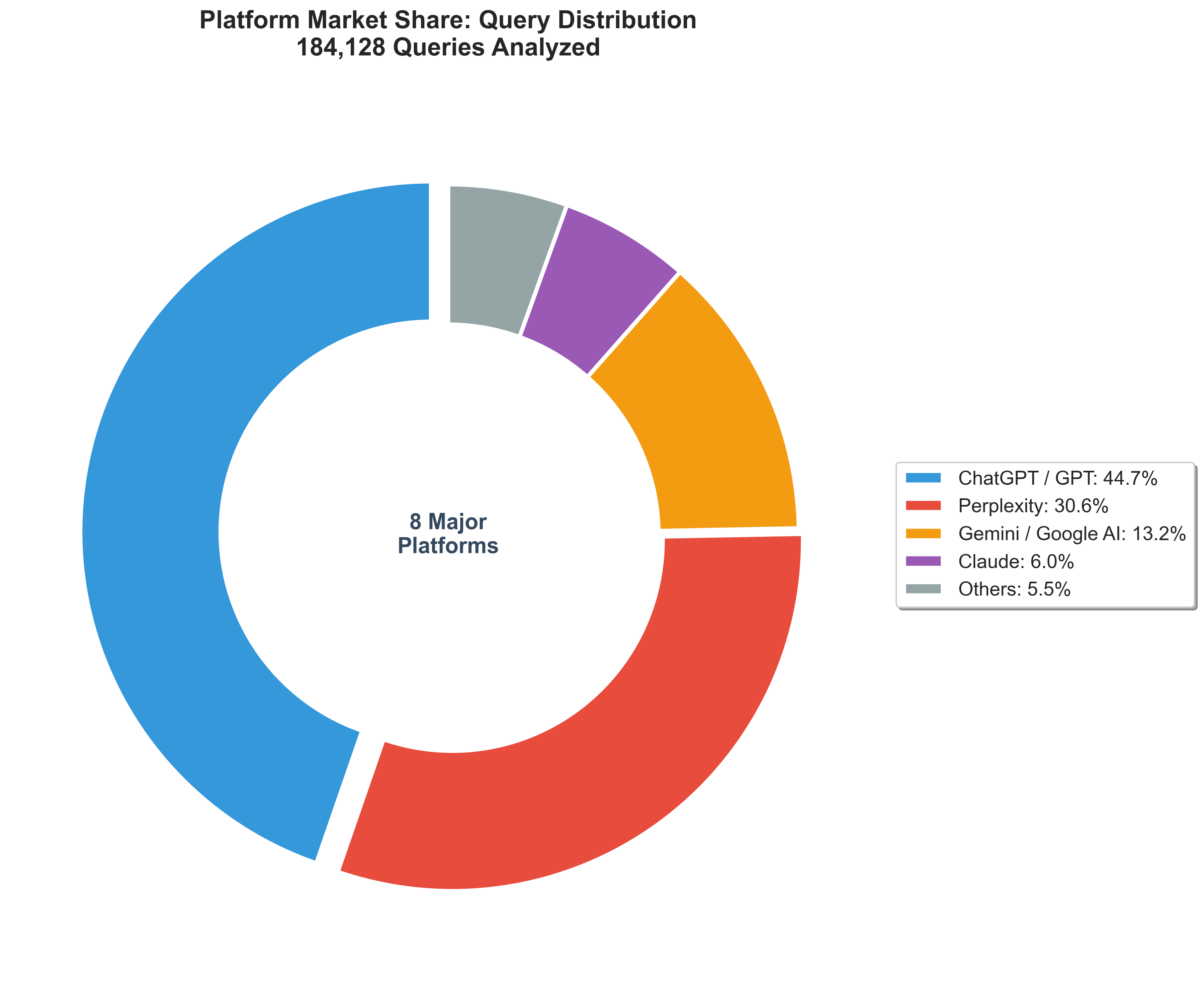
ChatGPT / GPT (OpenAI) - 82,268 queries (44.7%)
Includes: ChatGPT Core, GPT-4o-mini, GPT-5, GPT-4o
Best brand positioning (GPT-4o-mini: 64.85% top 3)
Most diverse sourcing (43,824 unique domains)
Competitor mention rate: 19.23% (GPT-5 ultra-selective) to 74.36% (GPT-4o-mini)
October 2025: ChatGPT Core became dominant model
Perplexity - 56,250 queries (30.6%)
Includes: Perplexity Core, Perplexity Sonar
Commercial content king (Core: 77.6%, Sonar: 56.2% commercial sources)
Total sources: 707,279 (highest volume)
Competitor mention rate: 58-64%
Strategy: Practical, actionable business content
Gemini / Google AI (Google) - 24,344 queries (13.2%)
Includes: Gemini 2.0 Flash, Google AI Overview, Gemini Core, Google AI Mode, Gemini 2.5 Flash, Gemini 2.5 Pro
Most diverse (Google AI Overview: 4.7% source concentration)
Worst brand positioning (Gemini 2.0 Flash: 37.18% top 3, position 7.74)
YouTube #1 source for Google AI Overview
Competitor mention rate: 53-71%
Claude (Anthropic) - 11,120 queries (6.0%)
Includes: Claude 3.7 Sonnet
Ultra-concise (1,059 characters avg)
ZERO sources cited (fundamentally different trust model)
Competitor mention rate: 47.57% (cites competitors but no sources)
Strategy: Focus on training data
Microsoft Copilot - 5,566 queries (3.0%)
Highest competitor mention rate (95.29% - almost guaranteed visibility!)
Excellent brand positioning (60.3% top 3)
Very diverse sourcing (4.44% concentration)
Strategy: TOP PRIORITY for optimization
Grok (xAI) - 4,100 queries (2.2%)
Very comprehensive (7.94 avg competitors mentioned)
Competitor mention rate: 86.59% (high probability)
Diverse sourcing
Strategy: Detailed competitive comparisons
Mistral - 347 queries (0.2%)
Includes: Mistral Medium, Mistral Small, Mistral Large
Highest competitor mentions ever (Mistral Medium: 11.69 avg)
ZERO sources cited (like Claude)
Competitor mention rate: 91-95% (very high)
Strategy: Training data focus
DeepSeek - 133 queries (0.1%)
Includes: DeepSeek Chat, DeepSeek Reasoner
Perfect competitor mention rate (DeepSeek Reasoner: 100%)
ZERO sources cited
Competitor mention rate: 88-100%
Small sample size but interesting pattern
To learn more about optimizing for specific platforms, see our guides on how to rank on ChatGPT and how to improve visibility on Perplexity.
Like any dataset, ours has inherent biases:
Our goal: Equip CMOs, SEO leads, and marketing professionals with data-driven insights to navigate the AI search revolution. We're not claiming to have solved LLM ranking. But we're confident this data can materially improve your brand's AI visibility.
The first critical insight: not all LLMs behave the same way. Understanding how each model structures its responses is essential for crafting content that resonates with specific platforms.
One of the most striking differences between models is how much they say.
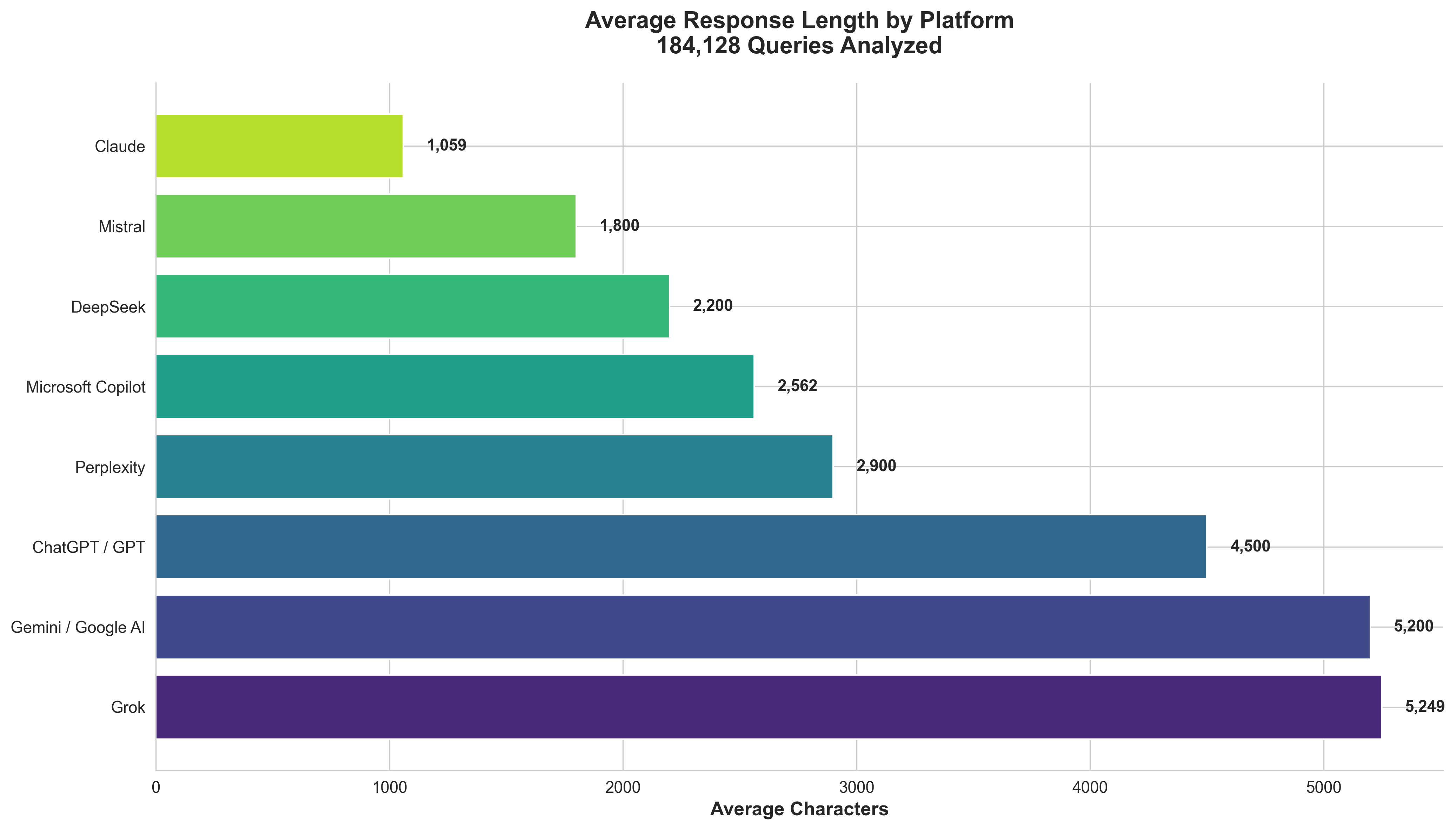 💡 Key Insight: Claude 3.7 Sonnet is 6x more concise than Google AI Overview. If you're optimizing for Claude, brevity is critical. For Google AI Overview, comprehensive, detailed content wins.
💡 Comparison to Previous Study: ChatGPT responses have grown 235% longer (from 1,687 to 5,650 characters), suggesting a trend toward more detailed answers.
💡 Key Insight: Claude 3.7 Sonnet is 6x more concise than Google AI Overview. If you're optimizing for Claude, brevity is critical. For Google AI Overview, comprehensive, detailed content wins.
💡 Comparison to Previous Study: ChatGPT responses have grown 235% longer (from 1,687 to 5,650 characters), suggesting a trend toward more detailed answers.
In the AI search era, ranking isn't about being in the "top 10." It's about being explicitly mentioned in the answer.
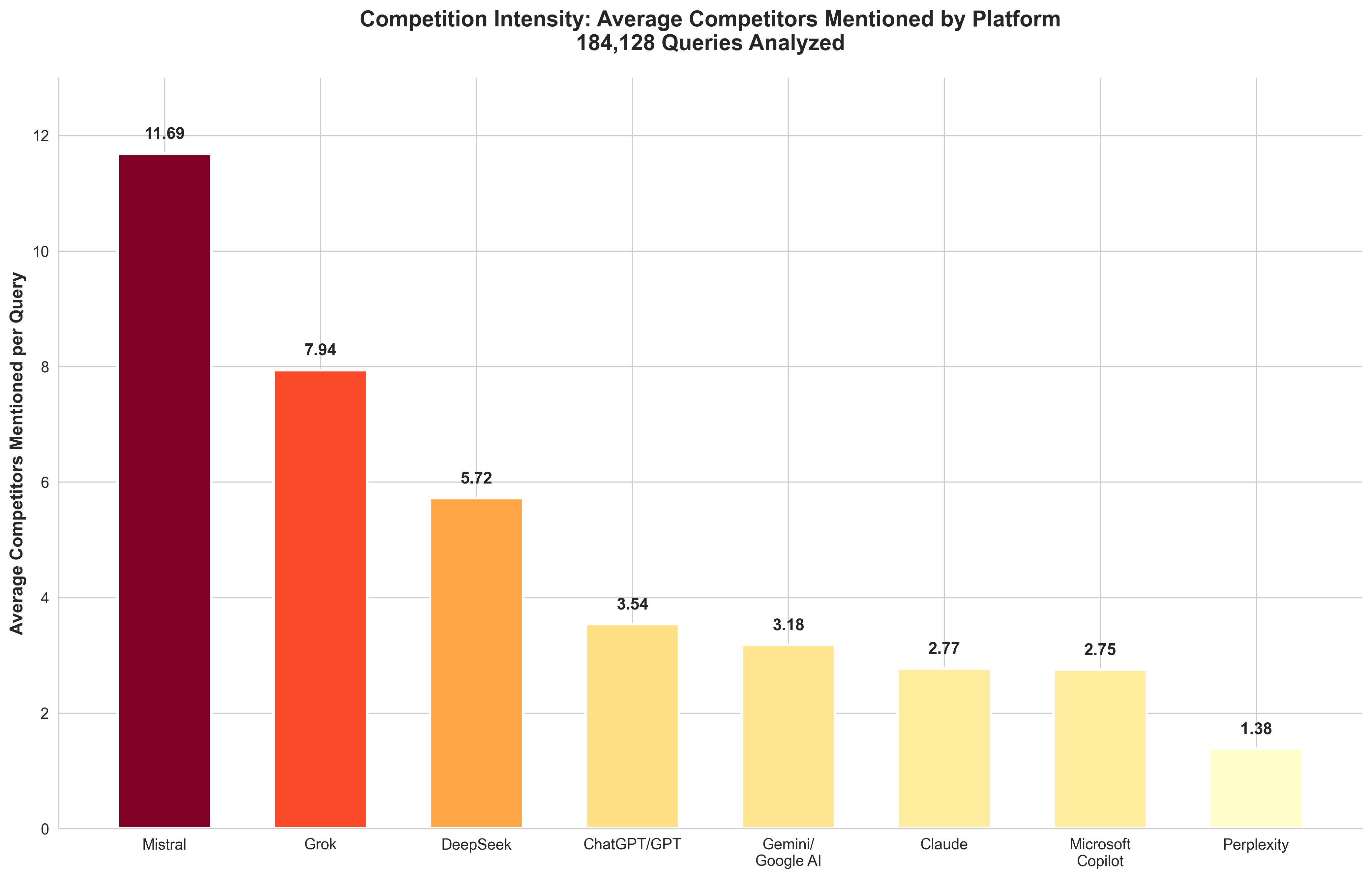 💡 BREAKTHROUGH INSIGHT: ChatGPT/GPT platform increased competitor mentions by 337% (from 0.81 in Q2 to 3.54 platform average in Q3)! ChatGPT Core specifically mentions 4.78 competitors per query (+490%). This is a MASSIVE shift in OpenAI's strategy - they're now recommending many more alternatives across all their models.
💡 NEW RECORD: Mistral mentions 11.69 competitors per query - the highest we've ever measured. If you're targeting Mistral, expect FIERCE competition with 10+ alternatives mentioned.
💡 Strategic Takeaway: The competitive landscape has intensified across all platforms. Only Perplexity remains highly selective (1.38 avg). For platforms like Mistral, Grok, and ChatGPT, ranking position is CRITICAL - there are 3-12 other competitors being mentioned.
💡 BREAKTHROUGH INSIGHT: ChatGPT/GPT platform increased competitor mentions by 337% (from 0.81 in Q2 to 3.54 platform average in Q3)! ChatGPT Core specifically mentions 4.78 competitors per query (+490%). This is a MASSIVE shift in OpenAI's strategy - they're now recommending many more alternatives across all their models.
💡 NEW RECORD: Mistral mentions 11.69 competitors per query - the highest we've ever measured. If you're targeting Mistral, expect FIERCE competition with 10+ alternatives mentioned.
💡 Strategic Takeaway: The competitive landscape has intensified across all platforms. Only Perplexity remains highly selective (1.38 avg). For platforms like Mistral, Grok, and ChatGPT, ranking position is CRITICAL - there are 3-12 other competitors being mentioned.
Language patterns reveal how LLMs "think." By analyzing the most frequently used expressions, we can optimize our content to mirror these patterns.
GPT-4o-mini (French):
"choisir" (choose) - 0.28%
"il est recommandé" (it is recommended) - 0.18%
"pour vous aider" (to help you) - 0.04%
"il est important de" (it is important to) - 0.04%
Gemini 2.0 Flash (French):
"choisir" (choose) - 0.69%
"il est important de" (it is important to) - 0.56%
"pour vous aider" (to help you) - 0.30%
"il est recommandé" (it is recommended) - 0.11%
Perplexity Sonar (French):
"choisir" (choose) - 0.40%
"il est recommandé" (it is recommended) - 0.05%
"profiter" (take advantage) - 0.05%
Claude 3.7 Sonnet (French):
"choisir" (choose) - 0.61%
"il est recommandé" (it is recommended) - 0.17%
Google AI Overview:
"try" - 2.34%
"choose" - 1.70%
"should" - 1.04%
ChatGPT Core:
"try" - 0.81%
"should" - 0.75%
"could" - 0.69%
"choose" - 0.49%
Grok:
"try" - 53.92% (!)
"choose" - 21.57%
"could" - 11.76%
💡 Key Insight: LLMs favor cautious, advisory language. Words like "recommandé," "should," "could," and "try" signal a consultative tone rather than definitive statements. 💡 Content Strategy: Incorporate these expressions naturally into your content. Use conditional phrasing ("you might consider") rather than absolute statements ("you must do").
We analyzed four linguistic patterns across all models:
1. Impersonal Form (e.g., "it is recommended")
Gemini 2.0 Flash: 38.4% of responses
Google AI Overview: 17.8%
Perplexity Sonar: 11.7%
2. Incentive Verbs (e.g., "discover," "choose")
Gemini 2.0 Flash: 37.5%
Google AI Overview: 25.2%
Perplexity Sonar: 17.5%
3. Conditional Phrasing (e.g., "could," "would")
Gemini 2.0 Flash: 26.4%
Google AI Overview: 18.9%
Perplexity Sonar: 17.6%
4. Imperative Mood (e.g., "try," "take advantage")
Gemini 2.0 Flash: 32.7%
Google AI Overview: 25.3%
Perplexity Sonar: 16.4%
💡 Key Insight: Gemini 2.0 Flash uses the most formal, cautious language. Perplexity Sonar is the most direct. 💡 Hypothesis: Writing in a style that mirrors your target LLM may improve visibility. Test this in your content.
99% of LLM responses use bullet points (-) to structure information. A typical LLM response looks like this: To learn about football, you should read:
Football Magazine
Football Best
The Complete Guide to Football
💡 Key Insight: LLMs love structured, scannable content. Use bullet points, numbered lists, and clear hierarchies in your content.
Key Takeaways:
Understanding how LLMs communicate is the first step to being included in their answers.
This study introduces five revolutionary analysis dimensions that have never been measured at this scale before. These insights fundamentally change how we should approach AI search optimization.
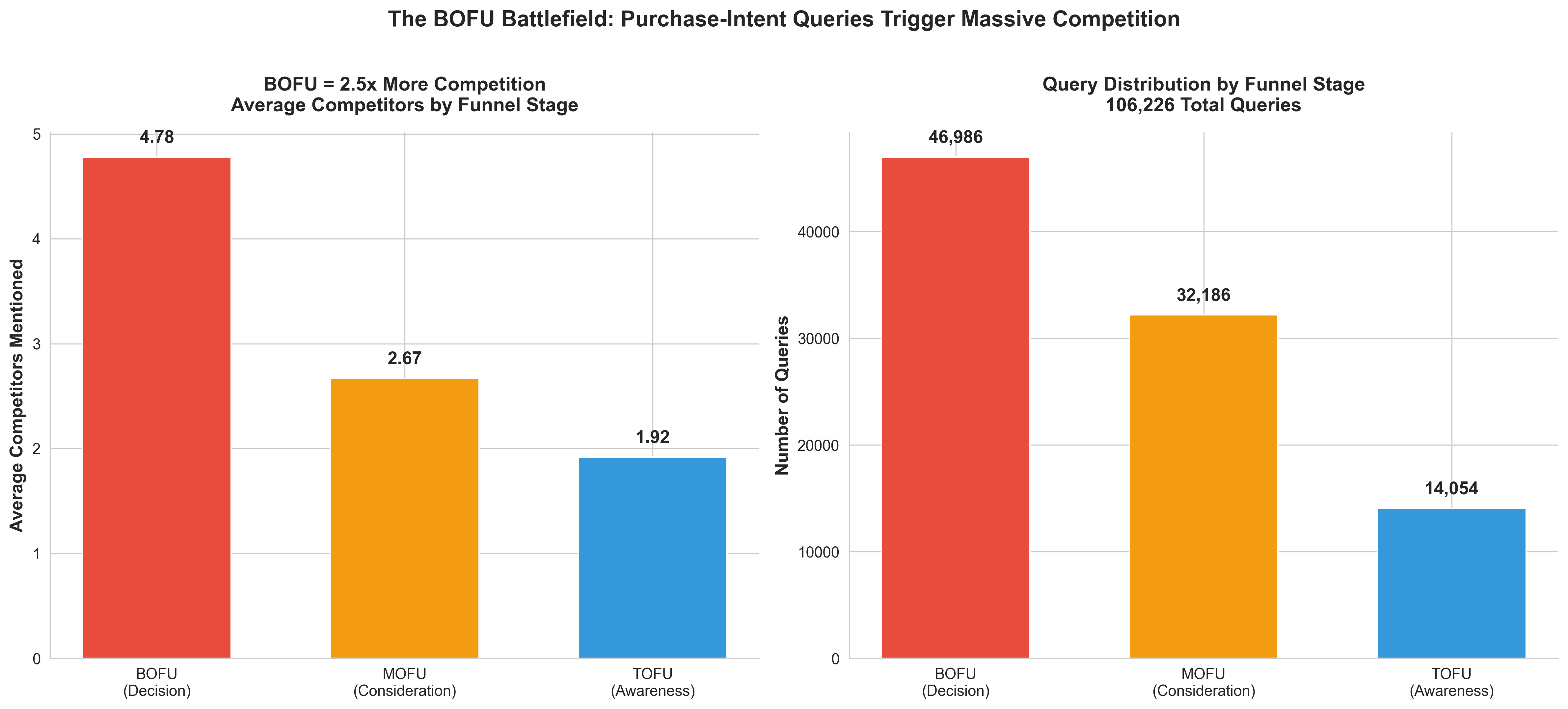
We analyzed how competitor mentions change based on query intent by categorizing queries into:
TOFU (Top of Funnel): Awareness stage - "What is project management software?"
MOFU (Middle of Funnel): Consideration stage - "Best project management tools for small teams"
BOFU (Bottom of Funnel): Decision stage - "Asana vs Monday.com pricing comparison"
The results are stunning:
💡 REVOLUTIONARY INSIGHT: The closer a user is to making a purchase decision, the MORE competitors LLMs mention. BOFU queries trigger 2.5x more competitor mentions than TOFU queries.
💡 The Paradox: TOFU queries cite MORE sources (2.86 vs 2.47) but FEWER competitors. Why? Because informational queries need diverse sources for credibility, while commercial queries are a competitive battleground where LLMs present multiple alternatives.
💡 Strategic Implication: If you're not ranking for BOFU queries, you're invisible at the moment that matters most. Users researching "best [category]" or "[brand] vs [brand]" comparisons will never discover you.
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
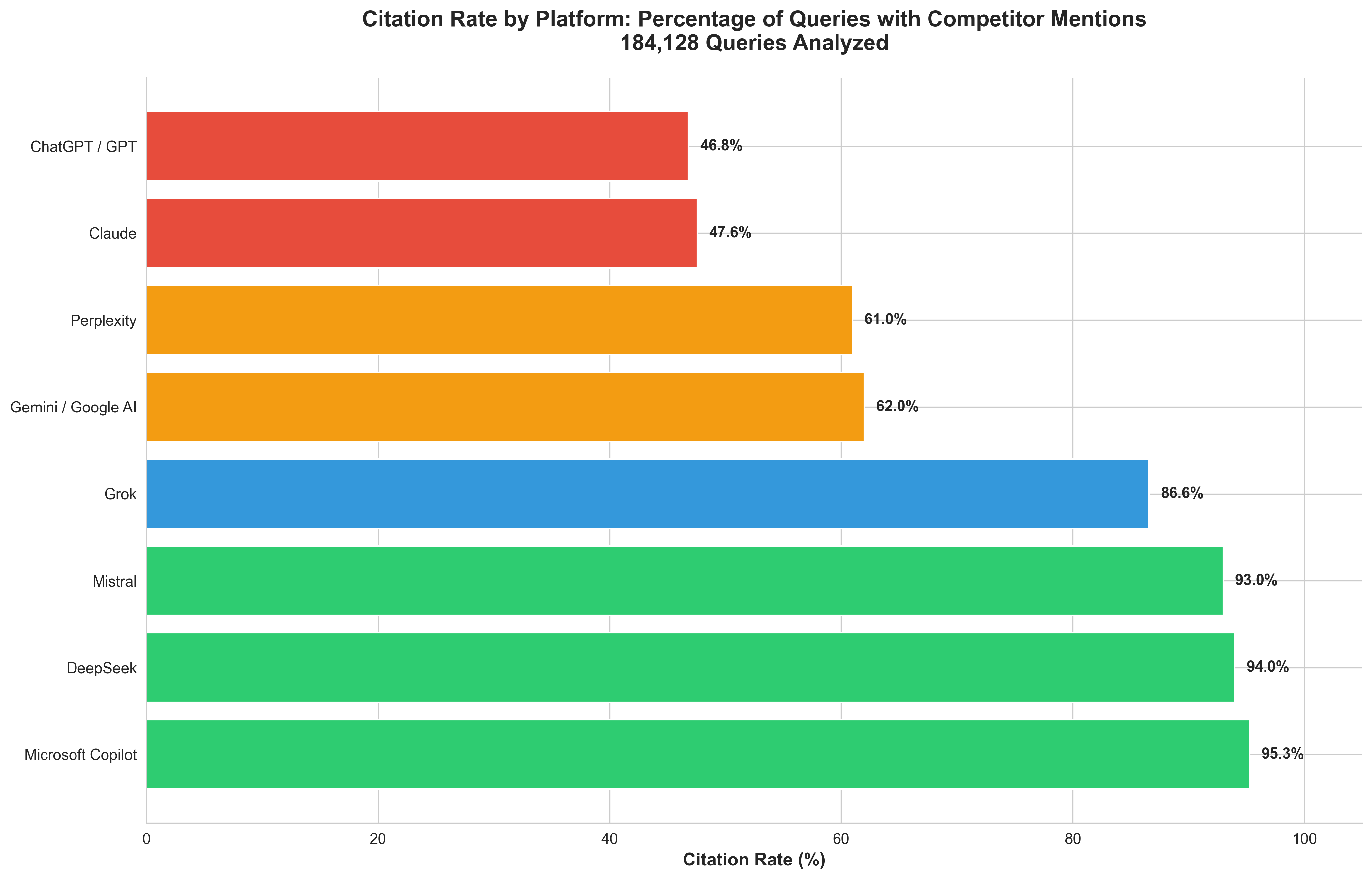
Not all platforms mention competitors with equal frequency. We measured competitor mention rate - the percentage of queries where at least one competitor is mentioned:
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
We analyzed the most common words appearing in cited URLs to identify content themes LLMs favor.
blog (60 occurrences)
pour (for) - 52
comment (how) - 35
choisir (choose) - 32
creation (creation) - 28
guide - 14
2025 - 20
2024 - 9
blog - 75
creation - 41
entreprise (business) - 29
comparatif (comparison) - 19
guide - 17
2025 - 15
blog - 79
creation - 45
entreprise - 35
guide - 22
comparatif - 17
2025 - 12
2024 - 10
blog - 123
saas - 27
guide - 24
best - 17
2025 - 9
2024 - 10
💡 Key Insight: "Blog," "guide," and "how-to" (comment) content dominates across all models. 💡 Date Insight: Unlike our previous study, 2025 doesn't dramatically outrank 2024. Content freshness appears less critical than we initially thought. Authority and relevance matter more. 💡 : Guides, comparisons, and educational content are heavily favored.
Track your mentions across ChatGPT, Claude, Perplexity and all major AI platforms. Join 1,500+ brands monitoring their AI presence in real-time.
Free trial • No credit card required • Complete platform access
Model | Avg Characters | Equivalent Words | Style |
Google AI Overview | 6,174 | 1,235 - 1,544 | Highly detailed |
ChatGPT Core | 5,650 | 1,130 - 1,413 | Comprehensive |
Grok | 5,249 | 1,050 - 1,312 | Balanced |
Gemini Core | 3,896 | 779 - 974 | Moderate |
Perplexity Core | 3,409 | 682 - 852 | Moderate |
Gemini 2.0 Flash | 2,963 | 593 - 741 | Concise |
Microsoft Copilot | 2,562 | 512 - 641 | Concise |
GPT-4o-mini | 2,524 | 505 - 631 | Very concise |
Perplexity Sonar | 2,233 | 447 - 558 | Very concise |
Claude 3.7 Sonnet | 1,059 | 212 - 265 | Ultra-concise |
Platform | Avg Competitors per Query | Approach | Change vs Previous Study |
Mistral | 11.69 | Most comprehensive ever | NEW |
Grok | 7.94 | Very comprehensive | NEW |
ChatGPT / GPT | 3.54 | Comprehensive | +337% (was 0.81!) |
Gemini / Google AI | 3.18 | Balanced | Stable (~3.77 Q2) |
Claude | 2.77 | Balanced | Stable |
Microsoft Copilot | 2.75 | Balanced | Stable |
Perplexity | 1.38 | Selective | Stable |
DeepSeek | 5.72 | Comprehensive | NEW |
Funnel Stage | Queries | Avg Competitors | Avg Sources | Competition Level |
BOFU | 46,986 | 4.78 | 2.47 | BATTLEFIELD |
MOFU | 32,186 | 2.67 | 2.43 | Moderate |
TOFU | 14,054 | 1.92 | 2.86 | Low |
UNKNOWN | 12,778 | 3.57 | 3.48 | Variable |
Competitor Mention Rate | Platforms | Strategic Implication |
90-100% | DeepSeek (88-100%), Microsoft Copilot (95.29%), Mistral (91-95%) | Nearly guaranteed citation - optimize here first! |
70-89% | Grok (86.59%) | High probability - strong ROI for optimization |
50-69% | Perplexity (58-64%), Gemini/Google AI (53-71%) | Selective - authority signals critical |
19-74% | ChatGPT/GPT (wide range!) | Varies by model - GPT-5 ultra-selective (19%), GPT-4o-mini frequent (74%) |
\< 50% | Claude (47.57%) | Ultra-selective - being mentioned = premium signal |
Platform Breakdown:
ChatGPT/GPT: 19% (GPT-5) to 74% (GPT-4o-mini) - HUGE variance
Perplexity: 58-64% - consistent selectivity
Gemini/Google AI: 53-71% - moderately selective
Mistral: 91-95% - almost always cites
DeepSeek: 88-100% - Reasoner has perfect record
💡 BREAKTHROUGH INSIGHT: Microsoft Copilot cites competitors in 19 out of 20 queries. If you're optimizing for ONE platform, make it Copilot - you're virtually guaranteed a citation.
💡 ChatGPT/GPT Range: Massive 19-74% spread within OpenAI models. GPT-5 is ultra-selective (1 in 5 queries) = premium signal. GPT-4o-mini is frequent (3 in 4 queries) = best ROI.
💡 DeepSeek's Perfect Record: 100% competitor mention rate for DeepSeek Reasoner. Every single query resulted in competitor mentions. Hyper-comprehensive but tiny sample.
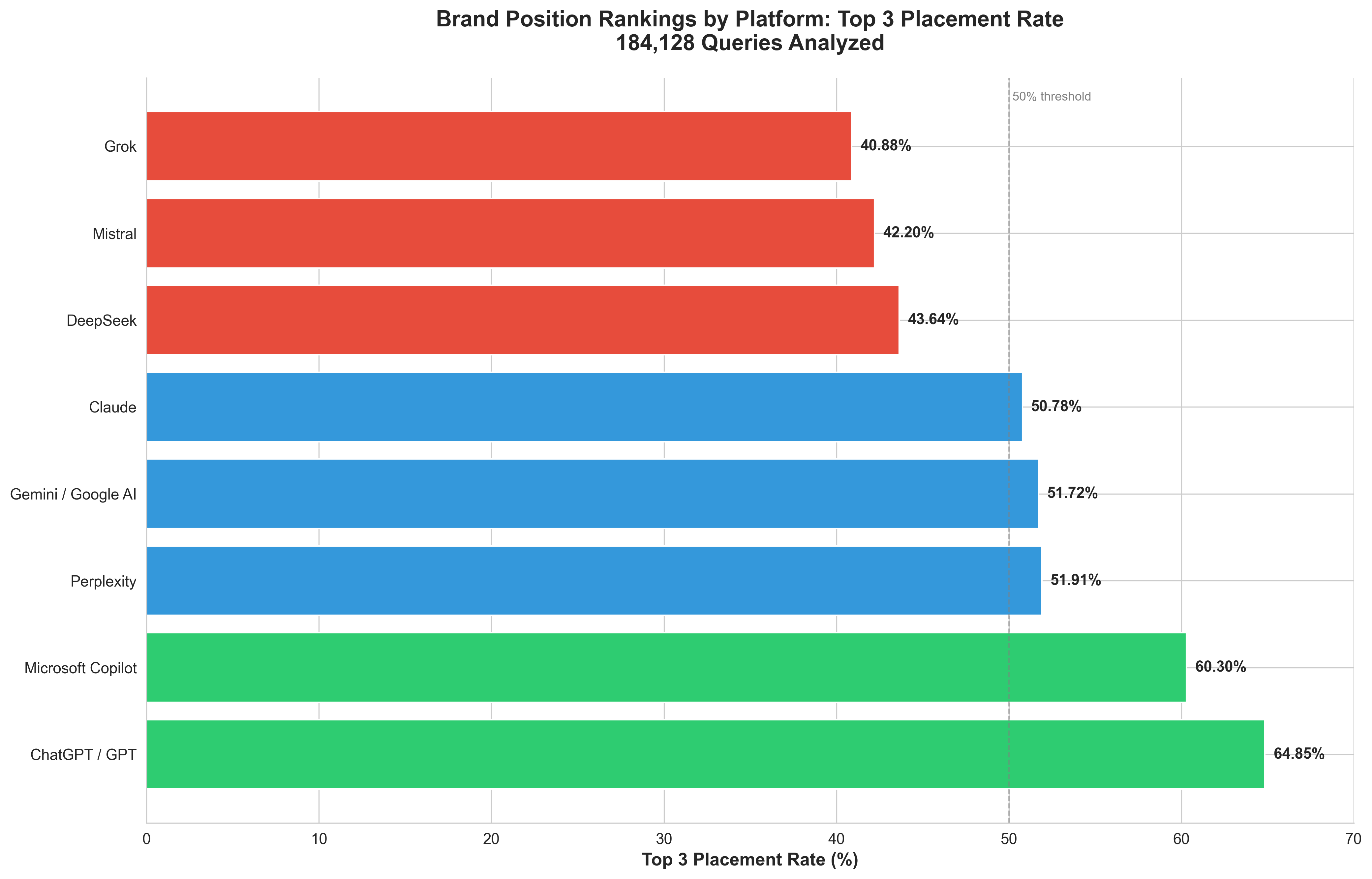
For the first time ever, we tracked where brands rank when they're mentioned by LLMs. Here's the Top 3 Placement Rate by platform - the percentage of mentions that land in the top 3 positions:
Rank | Platform | Avg Position Range | Best Top 3 % | Brand Visibility |
🥇 | ChatGPT / GPT | 3.55 - 5.11 | 64.85% | EXCELLENT (GPT-4o-mini best) |
🥈 | Microsoft Copilot | 3.47 | 60.30% |
Platform Details:
ChatGPT/GPT (BEST):
GPT-4o-mini: 3.55 avg, 64.85% top 3 ⭐
GPT-4o: 3.50 avg, 50% top 3
GPT-5: 3.79 avg, 47.37% top 3
ChatGPT Core: 5.11 avg, 39.47% top 3
Gemini/Google AI (MIXED - WORST to GOOD):
Gemini 2.0 Flash: 7.74 avg, 37.18% top 3 ❌ (WORST!)
Google AI Overview: 4.31 avg, 51.72% top 3 ⭐
Gemini 2.5 Flash: 5.58 avg, 36.87% top 3
Other Gemini models: 4.48 - 4.64 avg, 43-46% top 3
Perplexity:
Perplexity Sonar: 4.89 avg, 51.91% top 3
Perplexity Core: 5.64 avg, 39.26% top 3
💡 SHOCKING DISCOVERY: ChatGPT/GPT platform ranks brands nearly 2x BETTER than Gemini (64.85% vs 37.18% top 3). GPT-4o-mini alone provides massively better brand visibility than any Gemini model.
💡 The Gemini Problem: Gemini 2.0 Flash (9.9% market share) has average position 7.74 - meaning most brands are ranked 7th-8th. This is catastrophic positioning. Exception: Google AI Overview is much better (51.72%).
💡 Microsoft Copilot's Double Win: 95.29% citation rate + 60.3% top 3 placement = best optimization target in the entire study. Nearly guaranteed visibility AND excellent positioning.
💡 Winner: ChatGPT/GPT: With 44.7% market share AND 64.85% top 3 placement, OpenAI's platform delivers the best combination of volume and positioning.
We used the Gini coefficient (a measure of inequality used in economics) to understand source diversity:
0 = perfect equality (all sources cited equally)
1 = perfect inequality (one source dominates all citations)
Concentration Level | Platforms | Top 10 % Range | Gini Range | Strategic Implication |
VERY CONCENTRATED | ChatGPT/GPT (some models) | 84-100% | 0.54-1.0 | Narrow sourcing - GPT-5 uses elite domains repeatedly |
CONCENTRATED | Gemini/Google AI (most) | 15-68% | 0.72-0.76 |
Platform Breakdown:
Most Diverse (4-5% top 10):
Google AI Overview: 4.7% (Gini 0.646) - cites hundreds of sources
Microsoft Copilot: 4.44% (Gini 0.459) - very distributed
Grok: 5.29% (Gini 0.601) - broad sourcing
Balanced (10-13% top 10):
ChatGPT/GPT (average): 11.55-11.65% (Gini 0.60-0.70)
Perplexity: 9.52-13.01% (Gini 0.775-0.833) - BUT high inequality
Concentrated (15-100% top 10):
Gemini/Google AI (Gemini Core, 2.5, 2.0): 15-100% (Gini 0.72-0.76)
ChatGPT/GPT (GPT-5 only): 84.48% (Gini 0.543) - ultra-narrow
💡 Platform Diversity Winners: Google AI Overview, Microsoft Copilot, Grok cite 20x more diverse sources (only 4-5% from top 10). You need massive source diversity (100+ domains) to rank here. 💡 Perplexity's Inequality Problem: Gini 0.833 (highest!) means a small number of elite domains (legalplace.fr, legalstart.fr) dominate citation volume. Build domain authority or you're invisible. 💡 ChatGPT/GPT Range: GPT-4o-mini is balanced (11.65%), but GPT-5 is ultra-concentrated (84.48%) - uses same elite sources repeatedly. Two completely different strategies within one platform.
We categorized all sources by type and discovered a universal pattern. Here's what each source type means:
Source Types Explained:
Commercial: Business websites, SaaS platforms, e-commerce sites, company pages (e.g., legalstart.fr, shine.fr, tool-advisor.fr)
Institutional: Government sites, educational institutions, official organizations (.gov, .edu domains)
Media: News outlets, journalism sites, magazines (e.g., lemonde.fr, lefigaro.fr, techradar.com)
Educational: Academic resources, university content, research institutions
Blog: Independent blogs, personal sites, content platforms (e.g., medium.com, leblogdudirigeant.com)
Community: Forums, Q&A platforms, social discussion sites (e.g., reddit.com, quora.com)
Here's how LLMs distribute their citations across these source types:
Platform | Commercial % | Institutional % | Media % | Preference |
Perplexity | 66.8% | 6.2% | 5.3% | Heavy commercial |
Microsoft Copilot | 68.2% | 3.1% | 15.2% | Heavy commercial |
Platform Breakdown (Models with sources):
Heavy Commercial (65-78%):
Perplexity Core: 77.6% commercial (250,018 citations!)
Perplexity Sonar: 56.2% commercial
Microsoft Copilot: 68.2% commercial
Grok: 64.0% commercial
Moderate Commercial (45-55%):
ChatGPT Core: 73.7% commercial
GPT-4o-mini: 45.5% commercial (more balanced)
Exception - GPT-5: 27.6% commercial, 72.4% INSTITUTIONAL!
Gemini 2.0 Flash: 55.4% commercial
Google AI Overview: 47.3% commercial
💡 Universal Commercial Preference: ALL platforms (except GPT-5) favor commercial sources (business sites, SaaS platforms, services). If you're a business, this is great news - LLMs prefer company websites over media. 💡 Perplexity = Commercial King: 250,018 commercial citations (77.6% of Core). If you're in B2B/SaaS, Perplexity is your best friend. 💡 ChatGPT/GPT Range: Varies wildly within platform - GPT-5 prefers 72.4% institutional (.gov/.edu) while ChatGPT Core favors 73.7% commercial. Completely different trust models. 💡 Strategic Takeaway: For 7 out of 8 platforms, building commercial authority (strong E-E-A-T, business credibility) is more valuable than media coverage. Exception: if targeting GPT-5 specifically, pursue .gov/.edu partnerships.
These five dimensions reveal fundamental truths about AI search:
The AI search era is not the future. It's now.
If Part 1 was about how LLMs respond and Part 2 revealed game-changing patterns, Part 3 is about what sources LLMs cite. Over 1,479,145 sources were analyzed across all queries - a 2,365% increase from our Q2 2025 dataset (59,992 sources). The patterns are fascinating.
Not all models cite sources equally. Some models provide extensive sourcing, while others (like Claude, Mistral, and DeepSeek) provide ZERO source citations.
Model | Total Sources | Unique Domains | Avg Sources/Query | Sourcing Approach |
Perplexity Core | 323,130 | ~15,000 | 9.8 | Very high volume |
Perplexity Sonar | 384,149 | ~40,000 | 16.4 | Highest diversity |
💡 Major Finding: Seven models provide ZERO source citations - Claude 3.7, Mistral Medium/Small/Large, and DeepSeek Chat/Reasoner. This is a radical departure from citation-based models and fundamentally changes how users perceive and verify their responses. 💡 GPT-4o-mini's Diversity Champion: Despite not having the highest source volume, GPT-4o-mini cites the highest number of unique domains (43,824), suggesting an incredibly diverse source pool. This aligns with its excellent brand positioning (64.85% top 3 placement). 💡 Google AI Overview's Depth: Averages 35.2 sources per query - nearly 6x more than GPT-4o-mini. This explains its 4.7% concentration (most diverse model in our study).
The sources LLMs trust reveal their underlying priorities. Here are the top 5 most-cited non-commercial domains for each major AI platform (excluding business/marketing sites):
Top 5 domains:
💡 Insight: ChatGPT shows a strong preference for community platforms (Reddit #1) and authoritative government sources - 4 of top 5 are official .gov/.gouv.fr domains, demonstrating trust in institutional authority.
Top 4 domains:
💡 Insight: Perplexity heavily favors video content and community platforms - YouTube #1 and Reddit #2 dominate, followed by French government resources for business creation.
Top 5 domains:
💡 Insight: Gemini shows Google's own properties dominance (YouTube #1) combined with government authority and professional networks (LinkedIn), reflecting a focus on credible, authoritative sources.
Top 4 domains:
💡 Insight: Microsoft Copilot shows diversity with science content, travel, and e-commerce platforms, suggesting a consumer-focused approach with practical, actionable information.
Top 5 domains:
💡 Insight: Grok heavily favors community platforms and established media - Reddit dominates (#1) at nearly 5x more than Forbes (#2), showing strong preference for user-generated content alongside authoritative business news.
Model | Unique Domains |
GPT-4o-mini | 43,824 |
Perplexity Sonar | 38,738 |
Google AI Overview | 38,235 |
Gemini 2.0 Flash | 29,274 |
Perplexity Core | 11,923 |
💡 Key Insight: GPT-4o-mini has the most diverse source pool (43,824 domains), while ChatGPT Core is the most selective (5,173). 💡 Strategic Implication: For GPT-4o-mini, long-tail domain authority matters. For ChatGPT Core, focus on top-tier authoritative sources.
Key Takeaways:
Now that we've analyzed how LLMs respond (Part 1), discovered breakthrough patterns (Part 2), and identified which sources they trust (Part 3), let's translate this into actionable strategies.
Based on our citation rate and brand positioning analysis, here's the recommended optimization priority order:
Tier 1 - Highest ROI (Optimize First):
Tier 2 - Strong ROI (Optimize Second):
Tier 3 - Selective (Advanced Optimization):
Reconsider Strategy:
💡 Key Strategy: Start with Tier 1 models where you get the best citation probability AND positioning. Only expand to Tier 2-3 after dominating Tier 1.
Our BOFU analysis revealed that purchase-intent queries trigger 2.5x more competitor mentions. This changes everything:
Old Strategy (Wrong):
Focus on TOFU content to build awareness
Hope users discover you early in their journey
New Strategy (Right):
Prioritize BOFU queries where buying decisions happen
Target comparison queries: "[Your Category] comparison", "Best [tool] for [use case]"
Optimize for decision-stage keywords
Action Plan:
💡 Why This Matters: If you're not visible at the BOFU stage, users will never discover you - even if you have the best product.
There is no "one-size-fits-all" GEO strategy. Each platform has distinct preferences:
Platform | Market Share | Citation Rate | Avg Top 3% | Content Strategy |
Microsoft Copilot | 3.0% | 95.29% | 60.3% | Commercial content + E-E-A-T. Diverse sources (4.44% concentration). HIGHEST ROI. |
ChatGPT / GPT | 44.7% | 19-74% | 64.85% |
Key Insights:
Highest ROI: Microsoft Copilot (95% citation + 60% top 3)
Biggest Volume: ChatGPT/GPT (44.7% market share)
Best Positioning: ChatGPT/GPT (64.85% top 3 via GPT-4o-mini)
Commercial King: Perplexity Core (77.6% commercial sources)
Most Competitive: Mistral (11.69 avg competitors)
Avoid: Gemini 2.0 Flash (37% top 3, worst positioning)
YouTube's prominence - especially on Google AI Overview (#1), Gemini (#9), and Perplexity (#6) - cannot be ignored.
Action: If you're not creating video content, you're invisible to a significant portion of AI search traffic.
99% of responses use bullet points. LLMs favor:
Clear headings
Numbered lists
Bullet points
Scannable formatting
Action: Restructure existing content to prioritize scannability.
Mirroring LLM discourse patterns - cautious phrasing, advisory language, conditional statements - may improve citation rates.
Test:
Replace "You must do X" with "It is recommended to do X"
Use "could," "might," "should" instead of "will" or "must"
Our data shows that 2024 content ranks nearly as well as 2025 content, contradicting the common belief that recency is paramount.
Implication: Focus on building evergreen, authoritative content rather than constantly refreshing for dates.
All major models favor commercial sources except GPT-5:
Perplexity Core: 77.6% commercial
ChatGPT Core: 73.7% commercial
Microsoft Copilot: 68.2% commercial
Action: Build commercial authority (strong E-E-A-T, business credibility) over media coverage. For GPT-5, pursue .gov/.edu partnerships.
Reddit, Quora, and Medium are increasingly cited, especially by Google AI Overview and ChatGPT.
Action: Engage authentically in community discussions. High-quality Reddit threads and Quora answers can become authoritative sources.
7 models provide ZERO sources - Claude 3.7, all Mistral models, and DeepSeek models. But they still have HIGH citation rates (47-100%).
Implication: Traditional "backlink" thinking doesn't apply. Focus on being part of training data - publish authoritative, widely-cited content that future models will ingest.
Metric | Q2 2025 Study | Q3 2025 Study | Change |
Total Queries | 32,961 | 184,128 | +459% |
Total Sources | 59,992 | 1,479,145 | +2,365% |
Models Tracked | 3 |
Key Evolution:
Microsoft Copilot is the highest ROI target - 95.29% citation rate + 60.3% top 3 placement = nearly guaranteed visibility. Follow with ChatGPT/GPT (44.7% market share, 64.85% top 3 via GPT-4o-mini) and Perplexity (30.6% market share, heavy commercial preference).
It depends on the model. Claude 3.7 Sonnet averages only 1,059 characters (ultra-concise), while Google AI Overview averages 6,174 characters (highly detailed). There's no universal length - optimize based on your target platform.
Yes! Our data shows that authority beats freshness. 2024 content ranks nearly as well as 2025 content. Focus on creating evergreen, authoritative content rather than constantly updating for recency.
BOFU content is critical. Purchase-intent queries trigger 2.5x more competitor mentions (4.78 avg vs 1.92 for TOFU). If you're not visible when users ask "Best [category]" or "[Brand A] vs [Brand B]", you're invisible at the moment that matters most.
These models use a fundamentally different trust model - they rely entirely on training data rather than real-time sourcing. They still have high citation rates (47-100% mention competitors), but provide zero attribution. To rank here, focus on becoming part of future training data through authoritative, widely-cited content.
It varies dramatically by platform:
Mistral: 11.69 avg (most competitive)
Grok: 7.94 avg
ChatGPT/GPT: 3.54 avg (was 0.81 in Q2!)
Perplexity: 1.38 avg (most selective)
Position matters more than ever when 3-12 alternatives are mentioned.
Yes, critically important. YouTube is the #1 source for Google AI Overview, #6 for Perplexity Sonar, and #9 for Gemini 2.0 Flash. If you're not creating video content, you're invisible to a significant portion of AI search traffic.
ChatGPT's massive shift: Competitor mentions increased by 337% platform-wide (from 0.81 to 3.54 avg), with ChatGPT Core specifically at 490% (4.78 avg). OpenAI dramatically changed its strategy to recommend many more alternatives. Combined with 106% month-over-month growth in AI search adoption, the competitive landscape has intensified dramatically.
AI search isn't the future. It's already here. The data is clear: AI-generated answers are replacing traditional search results. With 184,128 queries, 1,479,145 sources, and 20 models analyzed, we're seeing revolutionary patterns emerge:
At Qwairy, we're committed to publishing quarterly updates as the AI search landscape evolves. We've already exceeded 184,000 queries and will continue tracking:
New model releases and updates
International expansion (more languages, regions)
Deeper vertical-specific analysis
Real-time citation tracking
The brands that win in AI search will be those that:
Prioritize BOFU content
Optimize for high-ROI models (Copilot, GPT-4o-mini)
Build commercial authority
Create video content
Act now before competition intensifies
The opportunity window is NOW. Don't wait until everyone else has optimized. Are you ready?
Want to see where your brand ranks across all 20 LLMs? Start optimizing for AI search engines today.
What Qwairy helps you do:
Track your brand mentions across 20+ AI models
Monitor BOFU vs TOFU query performance
Analyze citation rates and brand positioning
Identify content gaps and opportunities
Generate GEO-optimized content
Learn more about Generative Engine Optimization (GEO) and how to track if your brand is mentioned in LLMs.
Methodology Note: This study analyzed 184,128 queries generated between July 27 and October 27, 2025, across 20 LLM models via API. All data was collected using Qwairy's GEO
🥉 | Perplexity | 4.89 - 5.64 | 51.91% | GOOD (Sonar better than Core) |
4 | Claude | 4.42 | 50.78% | AVERAGE |
5 | Gemini / Google AI | 4.31 - 7.74 | 51.72% | MIXED (AI Overview good, 2.0 Flash terrible) |
6 | DeepSeek | 4.74 - 5.72 | 43.64% | AVERAGE (small sample) |
7 | Mistral | 4.79 - 5.47 | 42.20% | BELOW AVERAGE |
8 | Grok | 5.11 | 40.88% | BELOW AVERAGE |
BALANCED | ChatGPT/GPT (main), Perplexity | 10-13% | 0.60-0.83 | Diverse but focused - good balance |
VERY DIVERSE | Microsoft Copilot, Grok, Google AI Overview | 4-5% | 0.46-0.65 | Massive diversity - 100+ domains matter |
ChatGPT/GPT | 54.3% | 5.1% | 7.4% | Commercial (varies by model) |
Gemini/Google AI | 51.7% | 3.8% | 6.2% | Commercial |
Claude | N/A | N/A | N/A | ZERO sources |
Mistral | N/A | N/A | N/A | ZERO sources |
DeepSeek | N/A | N/A | N/A | ZERO sources |
Grok | 64.0% | 4.7% | 16.6% | Heavy commercial |
GPT-4o-mini | 245,987 | 43,824 | 6.4 | Most diverse (43k+ domains!) |
Gemini 2.0 Flash | 232,848 | ~30,000 | 12.8 | High volume |
Google AI Overview | 133,427 | ~40,000 | 35.2 | Highest avg per query |
ChatGPT Core | 57,793 | ~10,000 | 1.3 | Very selective |
Microsoft Copilot | 19,005 | ~5,000 | 3.4 | Selective |
Grok | 70,669 | ~15,000 | 17.2 | High volume |
Claude 3.7 Sonnet | 0 | 0 | 0 | No sources |
Mistral (all) | 0 | 0 | 0 | No sources |
DeepSeek (all) | 0 | 0 | 0 | No sources |
5,173 |
Perplexity | 30.6% | 58-64% | 45% | Heavy commercial (Core: 77.6%, Sonar: 56.2%). Practical business content. Build domain authority. 707k sources. |
Gemini / Google AI | 13.2% | 53-71% | 37-52% | YouTube essential (Google AI Overview #1). BUT Gemini 2.0 Flash has WORST positioning (7.74). Mixed results. |
Grok | 2.2% | 86.59% | 40.88% | Very comprehensive (7.94 competitors). Detailed comparisons essential. |
Claude | 6.0% | 47.57% | 50.78% | Ultra-concise (1,059 chars). ZERO sources. Focus on training data only. |
Mistral | 0.2% | 91-95% | 33-42% | 11.69 competitors (most competitive!). ZERO sources. Training data focus. |
DeepSeek | 0.1% | 88-100% | 44% | Perfect citation (Reasoner 100%). ZERO sources. Tiny volume but interesting. |
+567% |
ChatGPT Avg Chars | 1,687 | 5,650 | +235% |
Gemini Avg Chars | 2,955 | 6,174 | +109% |
Perplexity Avg Chars | 2,029 | 2,233 | +10% |
ChatGPT/GPT Competitors | 0.81 | 3.54 (platform) | +337% (ChatGPT Core: 4.78 = +490%) |
Gemini Competitors | - | 3.18 | New |
Analysis Dimensions | 3 | 5 | New: BOFU, competitor mention rates, brand positioning, Gini, commercial content |