Perplexity is an AI-powered answer engine. Instead of showing a list of websites like Google, it gives users direct answers, often using just a few trusted sources. Learn how to make your brand one of them.
Perplexity is an AI-powered answer engine. Instead of showing a list of websites like Google, it gives users direct answers, often using just a few trusted sources. That means if your brand isn't one of those sources, you're invisible. The good news? You can improve your chances of being cited - just like with SEO, but with new rules sometimes called GEO. This guide will show you step by step how to boost your visibility on Perplexity, get more traffic, and make sure your brand is part of the conversation. Let's dive in.
Perplexity is not a search engine in the classic sense. It's an AI answer engine. To do that, it combines two technologies:
Like ChatGPT, Claude or Gemini, Perplexity is built on top of a foundational AI model (called "Sonar") trained on a massive corpus of text data: books, websites, academic papers, and more. This gives it general knowledge about almost every topic.
Here's where it gets really powerful. Perplexity doesn't just rely on what it has learned during training. It also performs a live web search every time a user submits a query - a process known as (Retrieval-Augmented Generation). This means it can access fresh, up-to-date information and cite actual sources.
Other Articles
How to Set Up AI Referral Tracking in GA4, Plausible and Matomo
Most analytics tools miss or misclassify AI referral traffic by default. This step-by-step guide shows you how to properly track visits from ChatGPT, Perplexity, Claude, Gemini, and other AI platforms in GA4, Plausible, and Matomo.
GEO Content Optimization: The Complete Guide to create content that get cited by ChatGPT, Perplexity & Co.
A complete, data-backed guide to Generative Engine Optimization (GEO) for SEOs. Covers how LLMs consume and select content, semantic optimization, E-E-A-T signals, page typology, and content maintenance — with primary sources throughout.
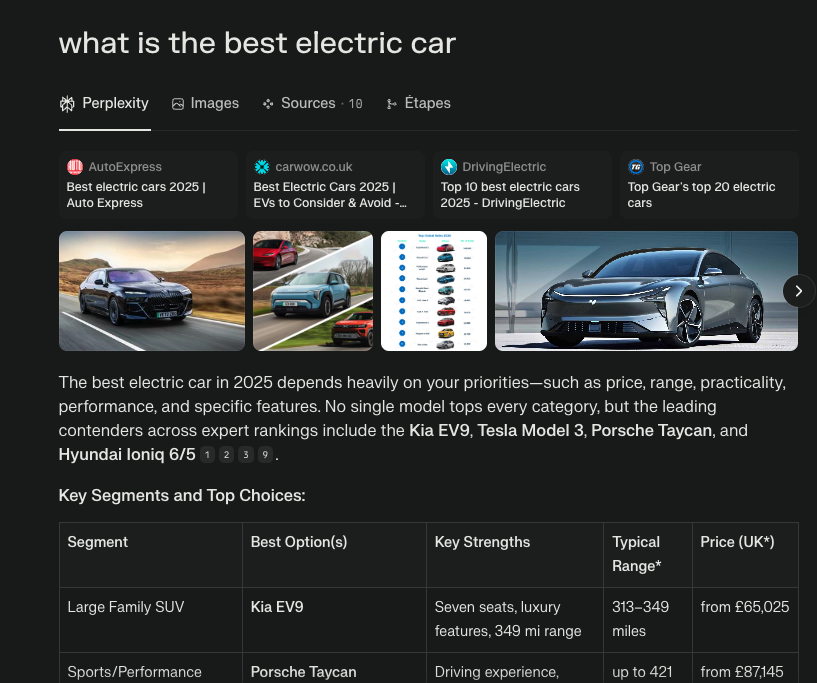
According to our findings, the process typically looks like this:
💡 Perplexity typically cites between 2 and 6 sources per query - far fewer than a traditional SERP. That means the bar for inclusion is much higher, but also that visibility is more powerful when you earn it.
Based on a study of 32,961 queries across Perplexity, Gemini and ChatGPT Search made by Qwairy, the most commonly cited domains include:
Youtube - the #1 source
Official government website
Comparison Website
In short: You don't optimize for keywords, you optimize to be the best possible answer. And that's what this guide will help you do - step by step.
Before you can improve your visibility on Perplexity, you need to know what your audience is asking. Unlike traditional SEO where you optimize for short keywords, Perplexity works with conversational prompts - full questions, often long and specific. Think:
"What is the best project management tool for small teams?"
not just
"project management tool".
Perplexity doesn't rank pages like Google. It builds answers based on relevance to the user's question, and it tends to cite only a few trusted sources. If your content doesn't match the intent and format of those prompts, you'll be invisible. So your first mission is to identify the right prompts. Here's how 👇
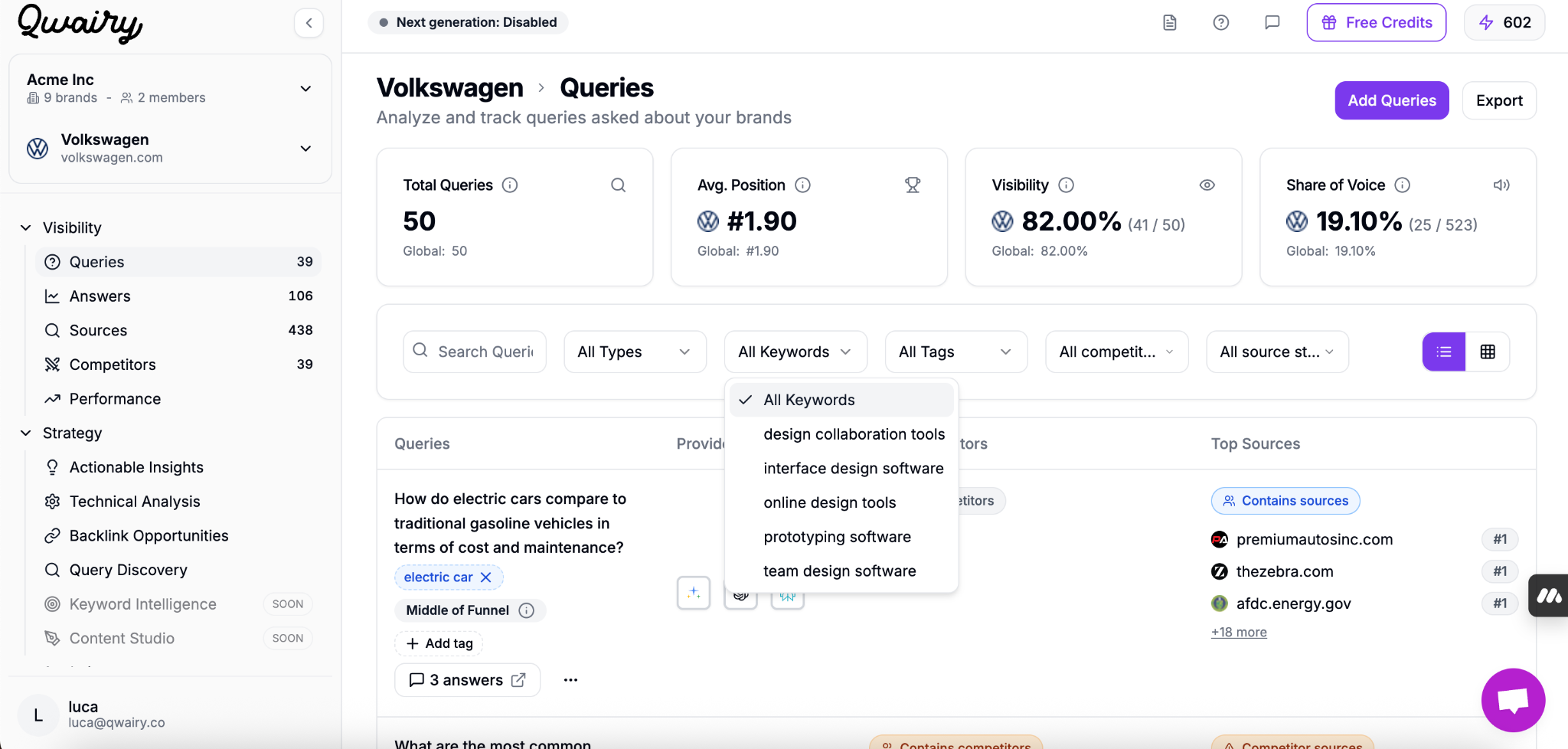
Qwairy is a GEO (Generative Engine Optimization) platform that helps brands identify which prompts users type into LLMs like Perplexity. You can:
Enter your brand name
Qwairy will analyze LLMs' perception of your brand
It will suggest relevant questions and keywords
It even shows which competitors are currently mentioned (and you're not)
💡 Qwairy uses insights from SERP data, People Also Ask boxes, and LLM outputs to generate real, and potentially high-volume prompts.
This gives you a starting list of questions to target with your content strategy.
Even though Perplexity doesn't give keyword data, you can use your Google Search Console to find real user questions. Most users ask similar things on Google and Perplexity. Apply this Regex to your queries:
^(who|what|where|when|why|how|which|can|should)\s
This will show you all the queries starting with questions - great candidates for Perplexity prompts. You can also use:
^(best|vs|top|cheapest|reviews)
These reveal comparison-style prompts, which LLMs love to answer.
Go to perplexity.ai and type in a basic keyword. Example: Type "best CRM for startups" and press enter.
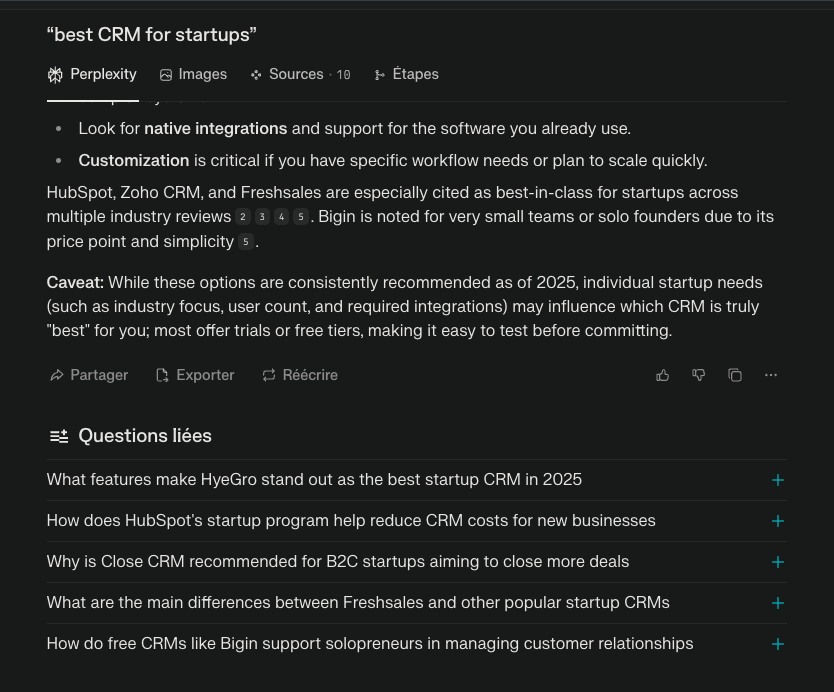
→ You'll get an answer, and underneath, a list of follow-up questions like:
"What CRM offers the best integrations?"
"How does HubSpot compare to Zoho?"
These related questions are golden - they're exactly what Perplexity users are clicking next. They reveal intent, framing, and language you should reuse in your own content.
Other LLMs like Copilot or ChatGPT (especially with web access enabled) can give you prompt ideas too. Try asking:
"What are common questions users ask about \[your product or topic\]?"
Or even:
"What would a startup founder ask about CRM tools?"
These tools simulate user behavior and often suggest very natural, high-intent prompts.
Don't forget your internal knowledge:
What questions come up in your sales calls?
What does your customer support team answer every day?
What questions perform well in your Google Ads or blog articles?
Many high-performing prompts are hiding in plain sight.
You need to build your visibility on real, high-intent prompts - not keywords. Use Qwairy, regex filters, and the LLMs themselves to reverse-engineer the questions your users care about. Then, you'll know exactly what to write for. The future of SEO is topical. You don't optimise for keyword anymore : you build a content media optimise for everything that your client might search on the web.
💡 A good read about [how SEO is evolving from Keyword to Topic from Kevin Indig](https://www.growth-memo.com/p/topic-first-seo-the-smarter-way-to).
An other good read on our blog about [How to identify prompts users type into AI search engines](https://www.qwairy.co/blog/how-to-identify-prompts-ai-search-engines)
Once you've identified the prompts your audience is typing, the next step is to measure where your brand currently stands. In traditional SEO, you'd check your Google rankings. In the world of LLMs like Perplexity, the logic is different - but just as measurable. Your brand can appear in two different ways on Perplexity:
🏷️ As a Brand Mention - your name is cited as a product, service, or actor in the response
📚 As a Source - one of your webpages is directly linked or cited in the references
To succeed in GEO, you want to track both.
Start simple: go to perplexity.ai and type:
"What is \[Your Brand\]?"
"Is \[Your Brand\] a good \[product/service\]?"
"Best alternatives to \[Your Brand\]"
"Top \[category\] tools"
"Best tools for \[what your products do\]"
👉 Look at the answer.
Are you mentioned?
Are your competitors mentioned instead?
Is one of your pages cited below?
If you're not showing up at all, that's a red flag - but also an opportunity.
💡 Further read: This article about [how to track if your brand is mentioned on LLMs for free](https://www.qwairy.co/blog/how-to-track-if-your-brand-is-mentioned-in-llms) will help you.
Tools like Qwairy let you automate this process. Here's how it works:
Qwairy tracks which prompts are most relevant to your brand
For each prompt, it checks:
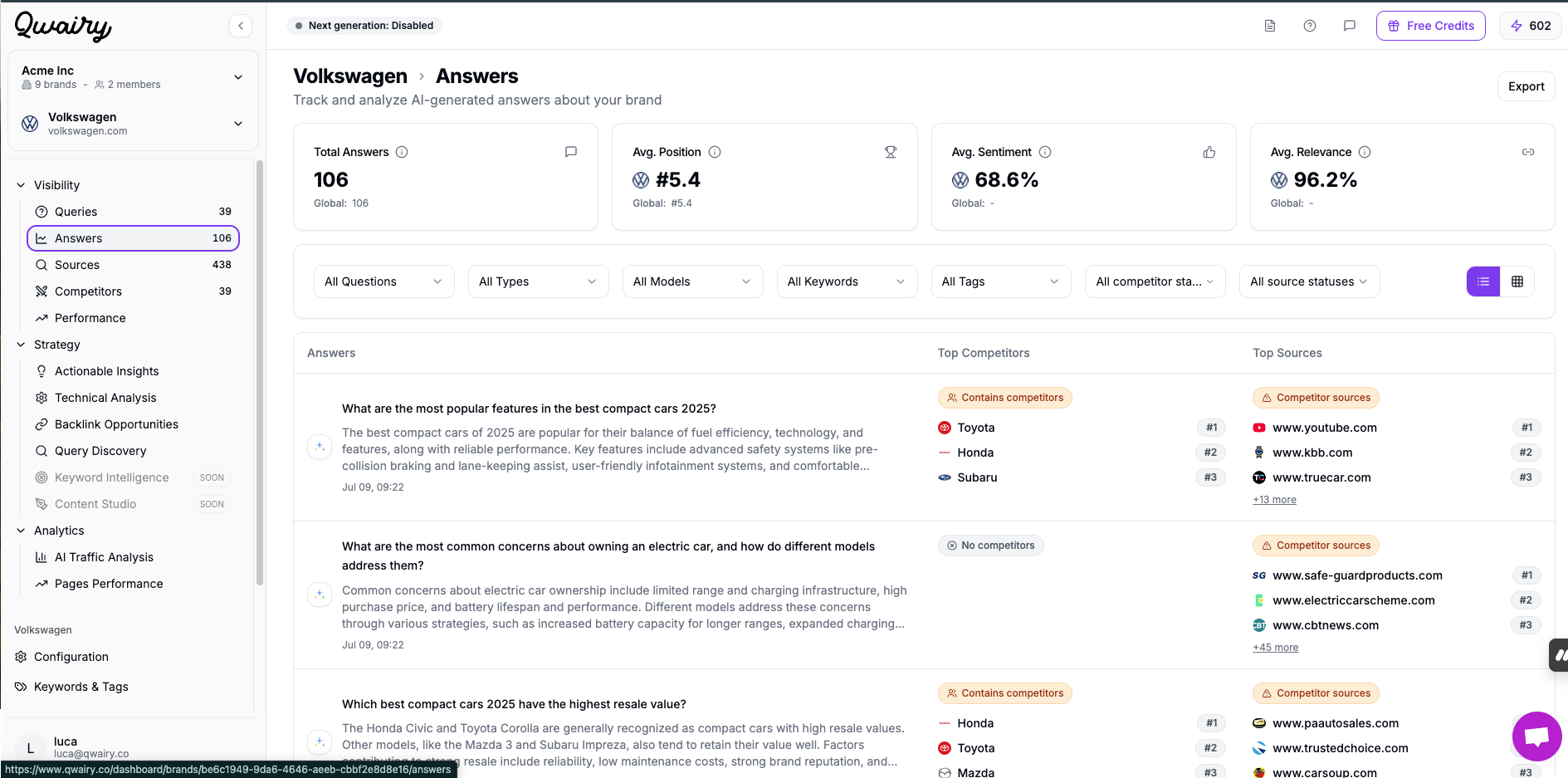
It even shows a score of visibility vs your competitors, so you can know exactly:
Who's winning attention
Where you're falling short
What content or domains are outranking you
Here is a video if you want to understand how Qwairy works:
💡 Bonus: You can filter by LLM (Perplexity, ChatGPT, Gemini) to see model-specific insights.
Run a free audit: see if ChatGPT, Gemini and Copilot recommend you, in about a minute.
If you don't use a GEO tool, you can still do it by hand. Here's a simple method:
This might take time, but it gives you full control over the audit. You can copy paste the following table in your favorite Excel file:
Prompt / Question | LLM Tested | Date | Brand Mentioned? | Type of Mention | Notes |
"Best CRM for startups" | ChatGPT | July 2025 | Yes | Brand + Source | Linked to blog |
"Top running shoes 2025" | Perplexity |
Let's take an example: 🔍 Prompt: "What is the best drill brand in Europe?"
If Perplexity says "Bosch, Makita and DeWalt are top choices", then Bosch is mentioned as a brand
If the article cited is from "bestdrillreviews.com/bosch-vs-makita", then that page is listed as a source
Some prompts will only include brands. Others will only cite articles.
💡 There are **two ways** your brand can show up in a response from an LLM:
**1. Brand Mentions**
This is when the LLM **explicitly names your brand** as part of an answer.
**2. Source Mentions**
This happens when the LLM **uses content from your website or blog** as a source to build its response.
Now that you know the right prompts and where your brand stands, it's time to take action. This is where GEO (Generative Engine Optimization) really starts: shaping your content so Perplexity can find it, understand it, and want to cite it. Unlike traditional SEO where keyword density or backlinks dominate, GEO is about clarity, authority, and structure. LLMs don't "rank" you - they decide whether your content is useful for answering a question. Let's break down what works.
This is obviously the first step to optimise for LLM visibility. If you want to rank for a query you have to answer this query somewhere with a page or with a dedicated passage in a page.
Imagine: When you type a question, perplexity has to search the web and analyse documents in a couple of seconds. That means your document need to be very easy to digest. What this means in practice:
Use clear headers (H2/H3) for each topic
Write in short paragraphs
Use bullet points () - 99% of LLM-generated answers use them
Start answers with a summary sentence, then elaborate
🧠 Example:
"To choose the right CRM, consider your business size, budget, and required features."
Then:
- For startups: look for ease of use and low cost
- For enterprises: integrations and scalability matter
- For remote teams: check collaboration features
This makes it easier for the LLM to quote exactly the portion it needs.
Perplexity doesn't want fluff. It wants useful, fact-based content. Include:
Definitions (e.g. "GEO stands for Generative Engine Optimization, a strategy to improve visibility on AI search engines.")
Stats & data (especially from trusted third parties)
Comparisons (X vs Y is a frequent query style)
How-to steps and lists
📌 Pro tip: LLMs prefer impersonal and neutral tone - avoid "we believe", "our product", or too much promotional language. Focus on helpful content first.
LLMs trust content that already cites other sources. Why? Because they prefer verified, well-contextualized information.
Link to studies, white papers, or industry benchmarks
Use factual anchors ("According to a 2024 report by...")
Include quotes from experts
This creates second-degree credibility: you become a "source that trusts other good sources".
LLMs like structure - and structured data helps. Add:
FAQPage schema
HowTo markup for guides
Product and Review markup if relevant
This isn't as important for Perplexity as it is for Google, but it does help LLMs parse content more easily when crawling your page.
Don't just create new content - rework your best existing articles to match LLM patterns:
Add summaries and bullet points
Break long text into clearer sections
Reframe intros to be more question-based
Include terms and expressions seen in Perplexity answers
🧠 Example of a great opening:
"Looking for the best drill in 2025? We've analyzed the top models based on power, durability, and price. Here's what you need to know."
Perplexity (and LLMs in general) love comparison content. They can transform it easily to make an answer. A good GEO strategy is creating this content on your website and ranking well with this content so that LLM can use it easily. This is exactly what tally.so, a free form builder, did: their content Best free online form builders generates 10% of their signup on ChatGPT. We did a full analyse of their strategy in this video:
You've structured your content. You've aligned it with real prompts. But if your domain isn't trusted by Perplexity's underlying model - or cited by other trusted sources - you still might not appear. Like other LLM-based answer engines, it relies on a limited set of highly trusted sources. The model needs to ensure that what it cites is reliable, objective, and easy to summarize. So how can you become one of those trusted sources - or, at least, get cited by them?
In the Qwairy study, over 59,000 sources were identified across SearchGPT, Gemini, and Perplexity. While the data isn't split by model, strong patterns emerge. Among the most cited types of websites, we find:
Wikipedia - due to its structure, neutrality, and topical depth
Media outlets - especially high-authority news like The Guardian, NYT, Le Monde
Forums and community platforms - like Reddit or Stack Overflow
Comparison and review platforms - Trustpilot, G2, Capterra, Avis Vérifiés
Official or institutional sites - .gov, .edu, NGO pages
Topical niche experts - highly focused blogs or resource hubs (e.g. for SaaS, finance, law)
💡 Perplexity often selects just 2 to 5 sources per query, so being cited requires more than relevance - it requires authority and trust.
If your domain isn't yet highly authoritative, aim to get mentioned by those that are. Here's how:
Publish guest posts on relevant media or expert blogs
Run industry studies or surveys and pitch them to sector-specific publications
Get reviewed on aggregators (Capterra, Trustpilot, G2, ProductHunt)
Be listed in Wikipedia articles or open databases like Wikidata or Crunchbase
Each citation increases your "semantic reputation" - and boosts the chance of being pulled into LLM responses.
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
Even if you can't change your DA overnight, you can optimize signals that Perplexity and LLMs consider when evaluating a site:
Add a clear About page with credentials
Link to third-party references or data
Keep your privacy policy, contact and legal pages up to date
Avoid overly promotional language
Include expert bios or author credibility (especially in YMYL niches)
The more your content looks like it was written for real humans - and reviewed by actual experts - the better.
Perplexity may not index your site directly - but it might crawl the site that mentions you. Tactics:
Partner with associations or institutions (e.g. professional federations)
Collaborate with influencers or micro-creators who rank well in your niche
Sponsor whitepapers, podcasts, or newsletters that already appear in Perplexity citations
These efforts create second-degree exposure: your name is mentioned in a source that's already trusted.
Certain content types tend to earn more citations:
Comparisons: "Notion vs Trello - Which Project Tool Wins in 2025?"
Research: "The State of E-commerce Logistics in Europe"
Explainers: "What is generative engine optimization (GEO)?"
Checklists or how-to guides: Practical, step-by-step formats
These formats are more likely to be interpreted as useful, fact-based and shareable by LLMs.
Make sure your content includes:
Dates (e.g. "Updated July 2025")
Data (with citations)
Conclusions that summarize key takeaways
Use Perplexity regularly to search:
"Best \[product\] in 2025"
"Is \[category\] still relevant?"
"How to \[do X\] in \[industry\]"
📌 Write down:
Which domains are consistently cited?
Which formats are used?
What tone and structure seems to perform?
This will help you build a "citation map": a view of what Perplexity trusts - and how to become part of that network.
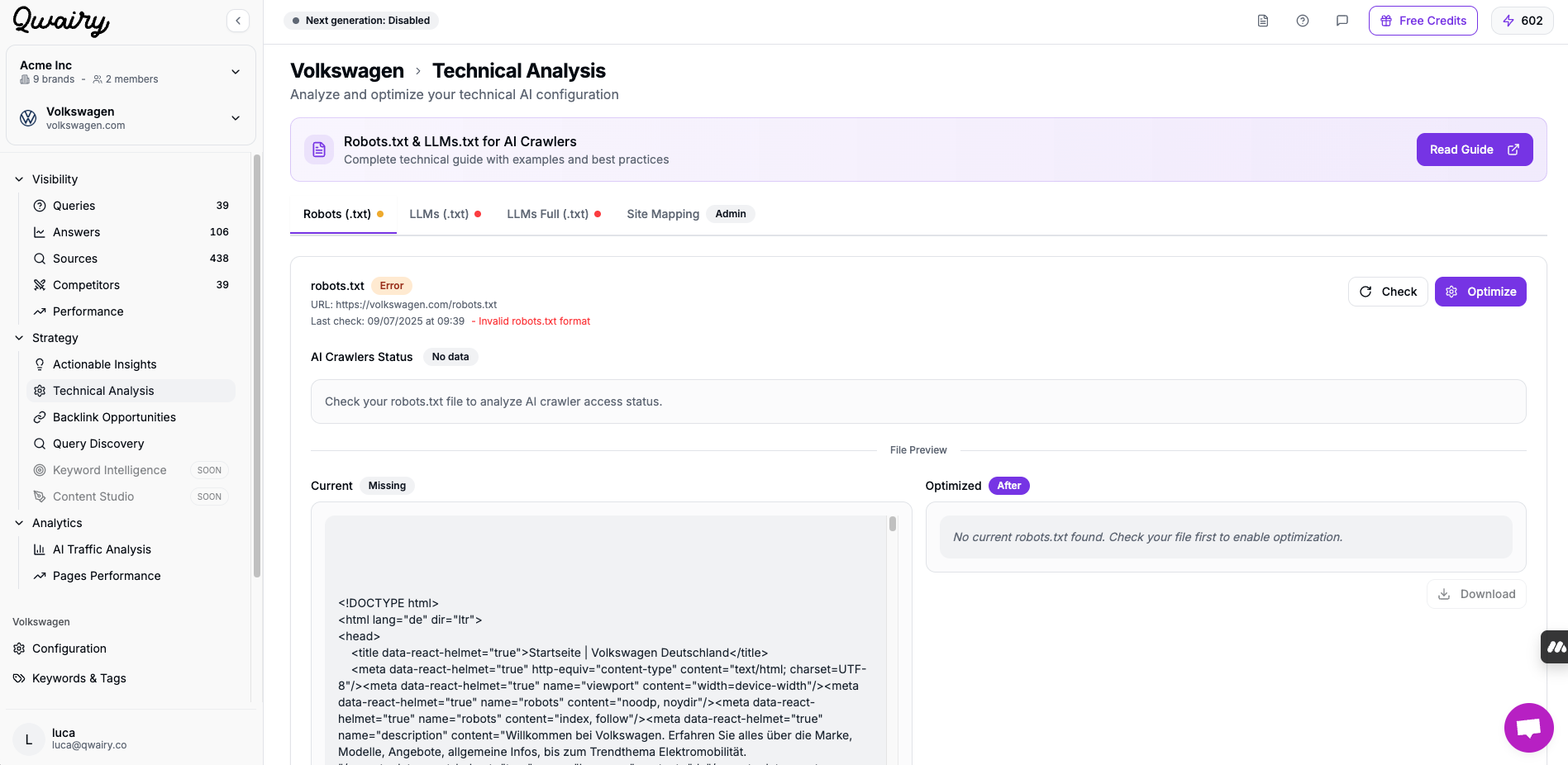
The first step is ensuring that Perplexity's engine can access your content. Perplexity uses a combination of its own crawling infrastructure and APIs from trusted search providers. Here's what to check:
✅ Your robots.txt allows crawling by LLM agents (e.g. User-agent: *)
✅ You're not blocking user agents like GPTBot, CCBot, or PerplexityBot
✅ Pages are not hidden behind login, paywalls, or JS-rendered navigation
✅ Avoid complex redirects or broken canonical tags
📌 Tip: Use a tool like Qwairy GEO audit to optimise your robots.txt for LLM crawler:
LLMs do look at meta information - not to rank you like Google, but to better understand what your page is about. ✅ Best practices:
Clear and informative <title> tags
Concise and neutral <meta description>
Schema where relevant (FAQ, HowTo, Article)
Avoid keyword stuffing or vague titles ("The Best Ever!" ≠ helpful)
LLMs access your page content similarly to browsers. If a page takes 5 seconds to load or requires JS rendering, it might not get parsed correctly. 📌 Actions to take:
Use image compression (WebP)
Avoid heavy JS dependencies
Implement lazy loading
Serve a fast, responsive mobile version
Test your site with tools like PageSpeed Insights or GTmetrix
Even though Perplexity doesn't show a visual preview of your site, slow or broken pages are still a barrier to being cited.
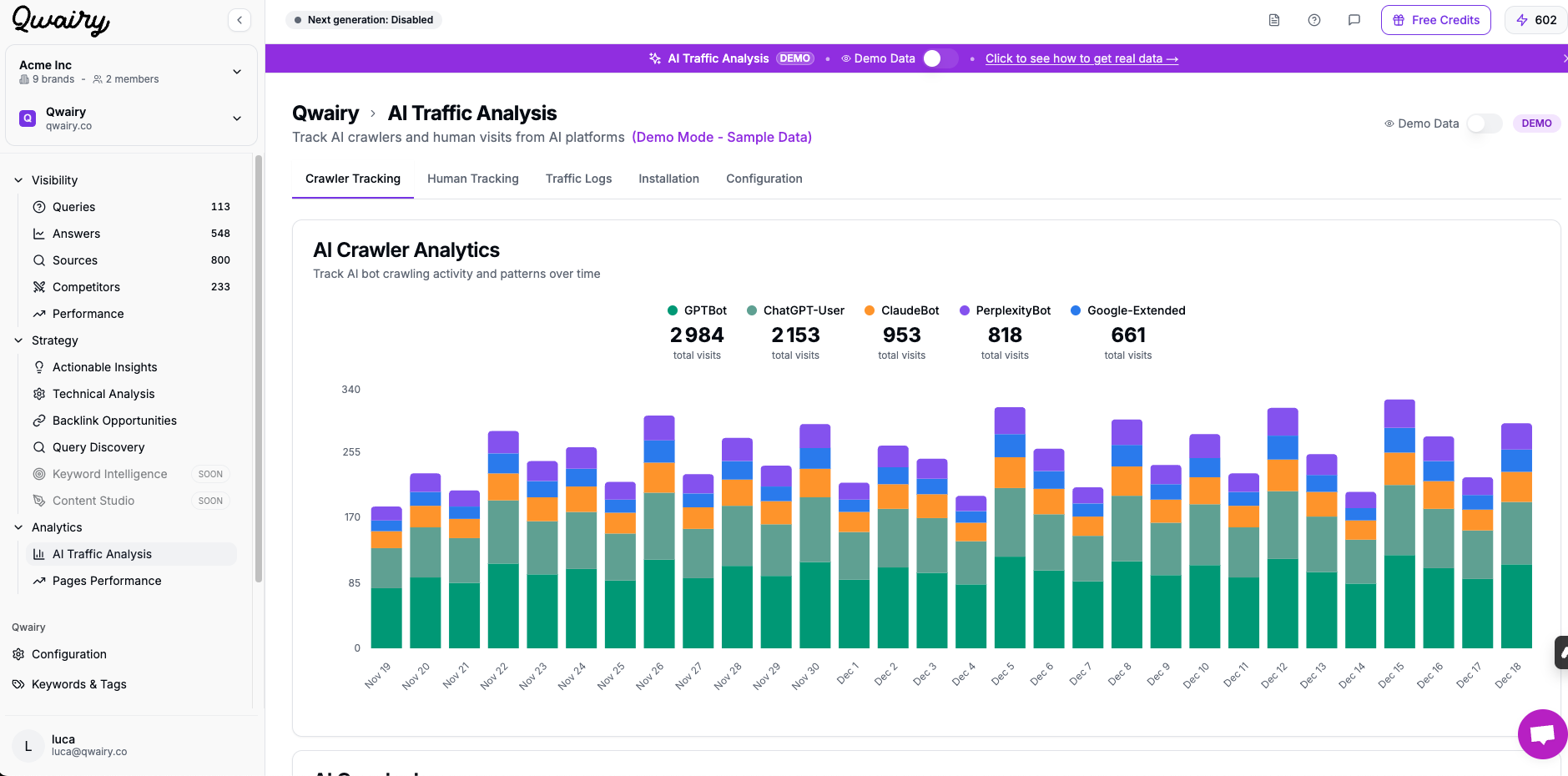
Use server logs or tools like Qwairy to check:
Which pages are being accessed by bots
How frequently they're crawled
Whether there are crawl errors (e.g. 403, 404, 503)
We offer a special tool on Qwairy to monitor log analysis:
💡 We build a complete [guide about AI Crawlers](https://www.qwairy.co/blog/understanding-ai-crawlers-complete-guide) that you should read 📖
Perplexity AI is reshaping how users search - and how brands get discovered. Unlike traditional search engines, it doesn't offer dozens of blue links. It chooses just a handful of trusted answers, favoring clarity, authority, and usefulness over everything else. If your brand isn't part of the answer, you're simply invisible. But that invisibility is not inevitable. By applying the GEO principles outlined in this guide, you can:
🎯 Identify real prompts your audience types
🕵️♂️ Measure your brand presence (as a source and a mention)
🛠️ Structure your content for LLMs, not just for Google
🔗 Build strategic citations and backlinks from trusted sources
⚙️ Optimize your site technically for LLM crawlers like PerplexityBot
Track your mentions across ChatGPT, Claude, Perplexity and all major AI platforms. Join 1,500+ brands monitoring their AI presence in real-time.
Free trial • No credit card required • Complete platform access
No |
- |
- |