Q2 2025 study on LLM ranking factors based on 32,961 queries across three LLMs. For the latest insights, see our Q3 2025 study with 184,128 queries.
**📊 UPDATE (October 2025)**: This study has been superseded by our [Q3 2025 study analyzing 184,128 queries](https://www.qwairy.co/blog/184128-queries-llm-study-q3-2025) - 5.6x larger with breakthrough findings on BOFU analysis, citation rates, brand positioning, and more. We recommend reading the latest study for the most current insights.
When we first launched Qwairy, our GEO tool, our mission was to help marketers improve their brand visibility in LLMs like ChatGPT, AI Overview (Gemini), and Perplexity. Search is evolving. The way we've browsed the web for the past 20 years is slowly being replaced by a new paradigm. I notice it every day. Just last weekend, I was with my mom. When she wanted to find a coffee shop, she immediately said:
"Let's see what ChatGPT recommends." While building Qwairy we quickly understood that marketing managers needed data to backup their analysis. After a lot of hard work, we're proud to present this comprehensive study, based on 32,961 queries across three LLMs (SearchGPT, Gemini, and Perplexity). Let's explore what we can learn to boost your brand's presence in LLM results.
Before we start we want to share with you how we generated and gather the data. All data was generated on our GEO tool Qwairy. Qwairy is a tool that helps you improve your brand presence on LLMs. Data comes either from our own brand analyses or from clients who have added their brands to the platform. In total, we generated 32,961 answers across three LLMs (SearchGPT, Gemini, and Perplexity), all between late 2024 and early 2025. We asked the same set of questions to each model. Each answer also includes the sources used by the LLMs - totaling 59,992 sources (since one answer can include multiple sources). Like any dataset, there are inherent biases. We aim to be as transparent as possible. All responses were generated via the LLMs' APIs. The models used were GPT-4-o-mini Search (also known as SearchGPT), Sonar (Perplexity), and Gemini 2.0. One important bias to note is that all data was generated through Qwairy by ourselves and our clients. Our dataset includes a variety of brands (e-commerce, SaaS, blogs, etc.). We plan to conduct this analysis quarterly to support SEOs, marketers, and CMOs. As more people use Qwairy, each report will become more comprehensive. Finally, it's worth noting that most of our current clients are French-speaking. We are increasingly onboarding international clients, so future reports will be more globally representative. That said, the SEO world has long been shaped by U.S.-based studies - and it's still turning. A little French perspective won't hurt. 😉 Our goal with this first study is to equip CMOs, SEO leads, and marketing professionals with the data they need to better understand how to rank in LLM-generated results. We're not claiming to have cracked the LLM ranking code - but we're confident this data can help you improve your presence on platforms like ChatGPT.
Other Articles
How Qwairy Predicts the 2026 World Cup Winner
A Qwairy research study on how AI answer engines frame the 2026 World Cup winner, where they agree, where answers become volatile, and what marketers can learn from AI perception mapping.
The Answer Is Now an Opening: How AI Engines Turn One Question Into a Funnel (June 2026)
We measured how AI engines END their answers on the commercial questions brands compete on: how often the engine closes by offering to keep going ("If you want, I can narrow this down by budget, region, use case"). Measured across the major AI engines we monitor over a 90-day window.
The first aspect we analyzed was the responses generated by the LLMs. We aimed to identify recurring patterns across these answers.
With Answer Engines and LLMs, a new paradigm is emerging in search marketing. It's no longer about appearing in the classic "top 10" Google results. Today, the goal is to be explicitly mentioned in the LLM's answer. If you're Tesla, and someone searches for the best electric car using an LLM, you want to be the first brand mentioned. Therefore the first analysis we did was about the number of competitors that were quoted on the different LLMs :
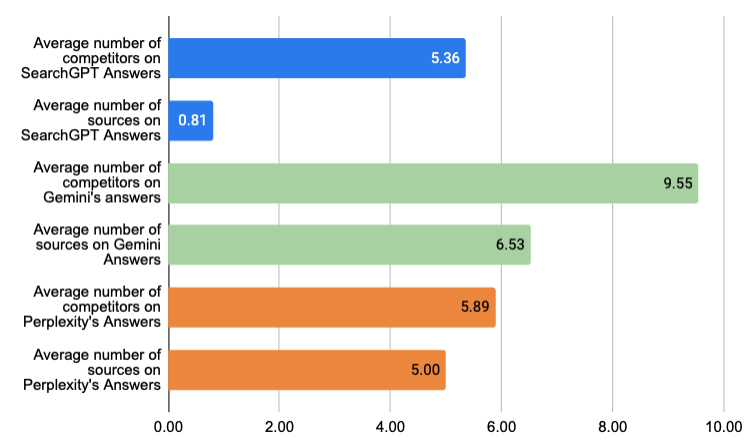
💡 Learnings : Ranking is not about 10 results anymore. To rank you need to be present as a brand in LLMs. 💡 Learnings : Gemini tends to quote more competitors than SearchGPT and Perplexity. This might be due to 💡 SearchGPT seems to be quoting only 0.81 average sources. There is a caveat because ChatGPT was not providing all the sources when we started Qwairy. We found a solution for this and the results would be more precise in the future.
The second thing we wanted to analyze was the number of characters by answers depending on the model that we use.
Model | Number of Character | Estimation Number of words (equivalent) |
SearchGPT | 1686.9 | 280 to 340 |
Gemini | 2955 | 490 to 590 |
Sonar | 2029 | 340 to 410 |
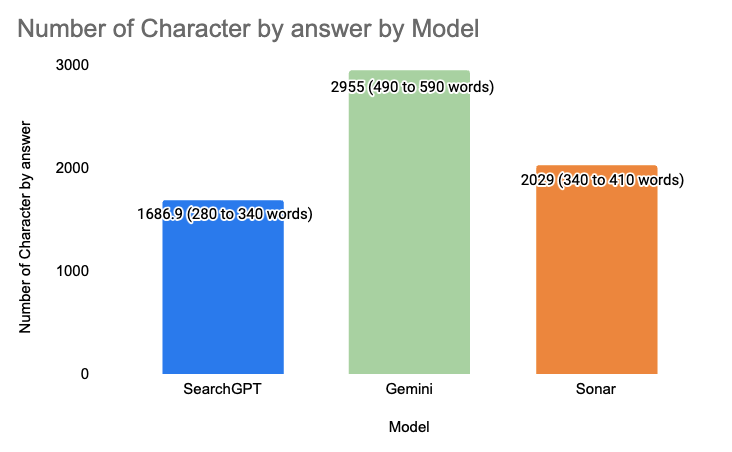
💡 Learning : Gemini seems to use more words than SearchGPT. If you want to be present on SearchGPT you might want to be as concise as possible as the model is using very few words to answer queries.
Most used expression by SearchGPT
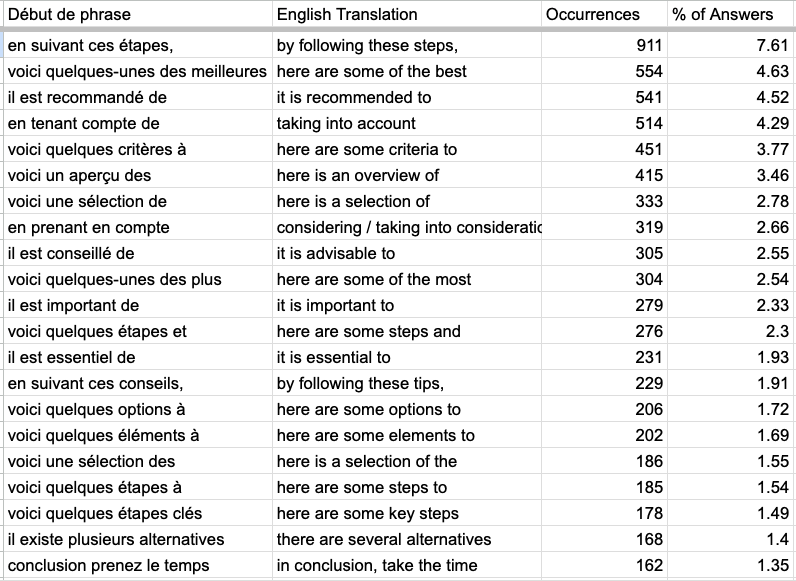
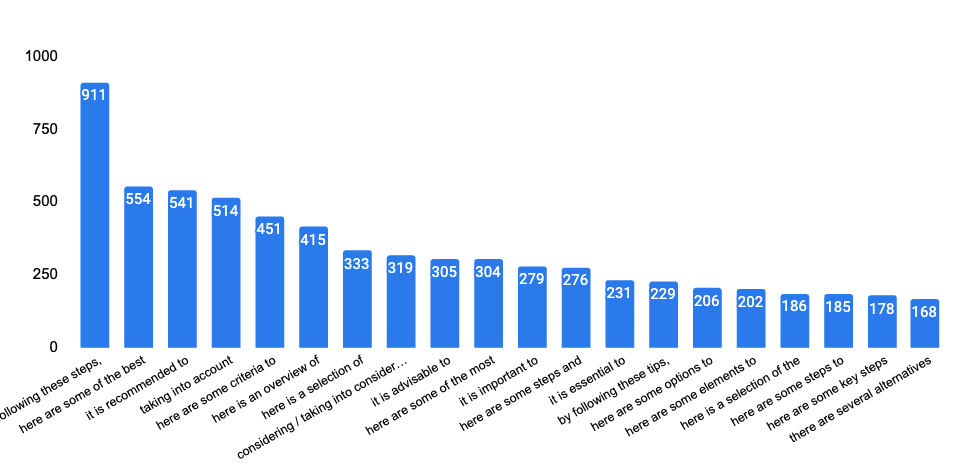
💡 Learnings : The expression "by following these steps" is present in 7.61% of all answers we generated (that's more than 11k answers). You might want to test adding this to your content 😉 Also note the presence of expression like "recommended", "considering", "take the time". LLMs are not perfect and they want to avoid any risk of giving a wrong advice. Please note that we translated this into english ourself but the expressions should be equivalent.
Most used expression by Gemini
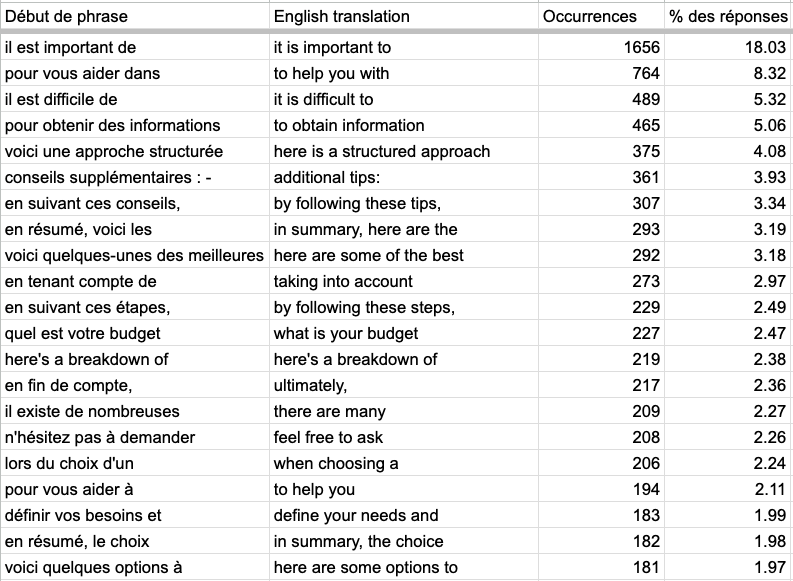
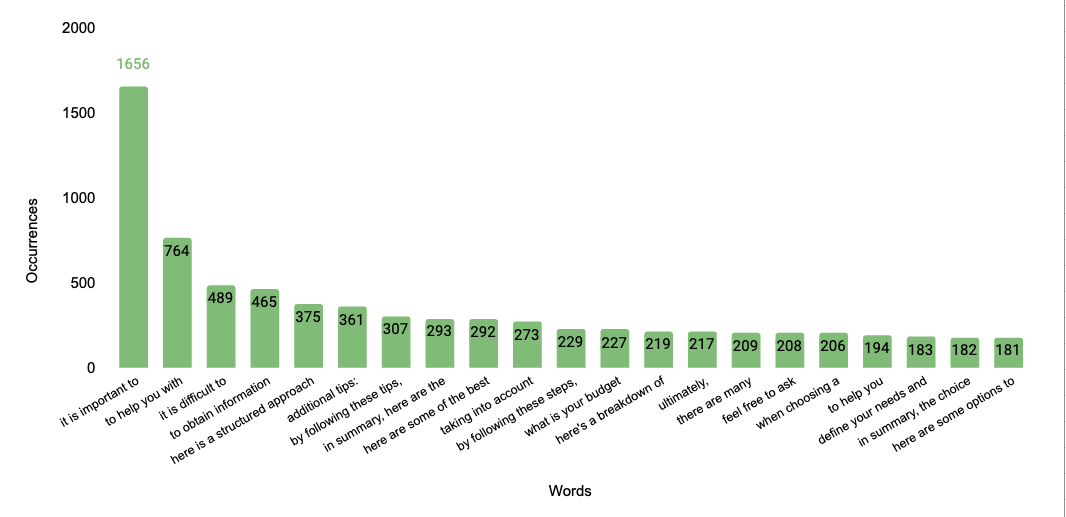
💡 Learnings : Most commonly used expression is "It is important to". This shows the importance for LLM to warn you about before your decision. Again there are common patterns between those expression like:
It is important to
To help you with
It is difficult to
Most used expression by Sonar
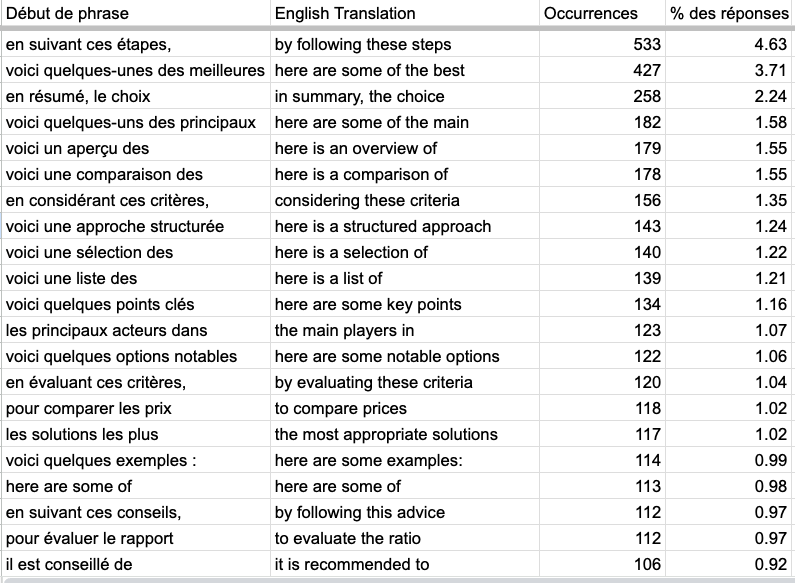
💡 Learning : Like SearchGPT, most used word by Sonar is "By Following these Steps". We asked the main questions to all LLM so this seems to be a very common phrase for LLMs.
Run a free audit: see if ChatGPT, Gemini and Copilot recommend you, in about a minute.
We also wanted to analyze the way LLMs talk. Our hypothesis is that if you talk like an LLMs you might get more chances to rank high (this is our personal hypothesis). LLMs need to process your content before using it and our hypothesis is that you would simplify their job by talking like they do.
How does SearchGPT talk? ✅ Impersonal form (e.g., "it is recommended") : Present in 17.8% of all SearchGPT answers. ✅ Incentive verb (e.g., "discover", "choose") : Present in 25.2% of all SearchGPT answers. ✅ Use of conditional (e.g., "could", "would") : Present in 18.9% of all SearchGPT answers. ✅ Use of imperative (e.g., "try", "take advantage") : Present in 25.3% of all SearchGPT answers.
How does Gemini talk? ✅ Impersonal form (e.g., "it is recommended") : Present in 38,42% of all Gemini answers. ✅ Incentive verb (e.g., "discover", "choose") : Present in 37,47% of all Gemini answers. ✅ Use of conditional (e.g., "could", "would") : Present in 26,41% of all Gemini answers. ✅ Use of imperative (e.g., "try", "take advantage") : Present in 32,69% of all Gemini answers.
How does Sonar talk? ✅ Impersonal form (e.g., "it is recommended") : Present in 11,68% of all Sonar answers. ✅ Incentive verb (e.g., "discover", "choose") : Present in 17,52% of all Sonar answers. ✅ Use of conditional (e.g., "could", "would") : Present in 17,60% of all Sonar answers. ✅ Use of imperative (e.g., "try", "take advantage") : Present in 16,35% of all Sonar answers. 💡 Learnings : As marketers we need to know how this tools talk for two reasons. First those tools are talking to our client and we might want to learn more precisely how they talk to them. Second those tools are analysing our site and we might have improve our presence by talking like them (this is an hypothesis at the moment).
99% of Answers use - when they talk. That means a typical answer by LLMS looks like this : To learn about football you should read :
Football Magazine
Football Best
…
Does that mean that you get more chances to rank if you use "-" in your content? You better test it 😉 That said this tends to prove that LLMs love structured answer and content that they can process and understand easily.
We observed clear differences between the models: Gemini tends to provide longer, more comprehensive answers, citing a greater number of competitors, while SearchGPT is more concise and selective in its citations. This distinction should influence how content is written and structured depending on the platform you're targeting. The most frequently used expressions and discourse structures also reveal consistent patterns. LLMs favor cautious, structured, and often impersonal communication, frequently relying on recommendations or conditional phrasing. By mirroring these linguistic patterns in our own content, we may be able to better align with their implicit selection criteria - a hypothesis worth exploring further. Finally, the near-systematic use of bullet points (with "-") shows that LLMs prefer clear, organized, and easily digestible formats. This is a simple yet powerful tactic to incorporate into any content strategy in the era of Answer Engines. In short, understanding how LLMs respond is key to understanding how to exist in this new ecosystem - and this is just the beginning.
Idée d'ajout d'infos (nom des concurrents) → Voir avec Nicolas les concurrents les plus cités ou les marques les plus citées dans notre corpus
The second part of this analysis is to analyze all the sources used by those LLMs. We truly believe that there is a big opportunity to increase your brand presence in LLMs if you are able to be present on their sources. Over the 32961 queries that were added on Qwairy, the LLMs quoted 59 992 different sources. We run two analysis to gather some data about this :
At website level : what are the website that are used as a source?
At url level : What is the specific url used as a source?
We also analyze the subject of the source and we have some insight about this.
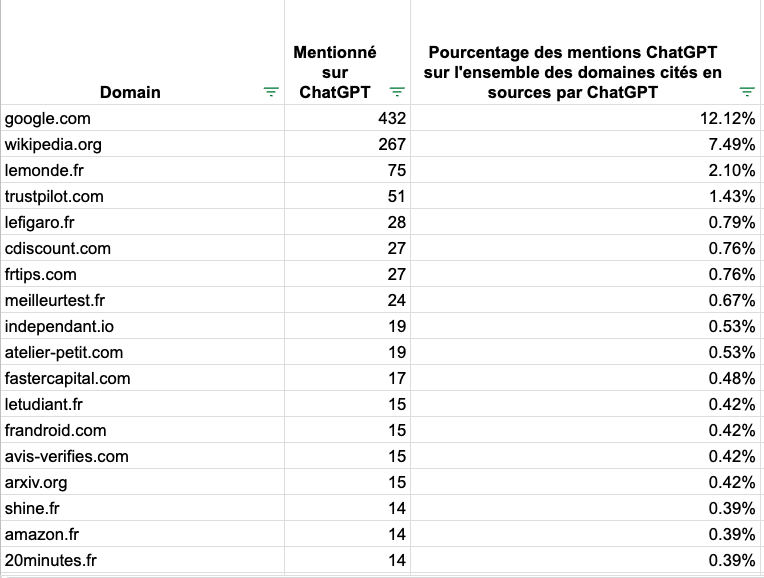
💡 Learnings : With no big surprise wikipedia is one of the most used website by SearchGPT as a source. Wikipedia was one of the main Also you'll notice that google is used regularly as a source. It is mainly website like Google Maps or other google services.
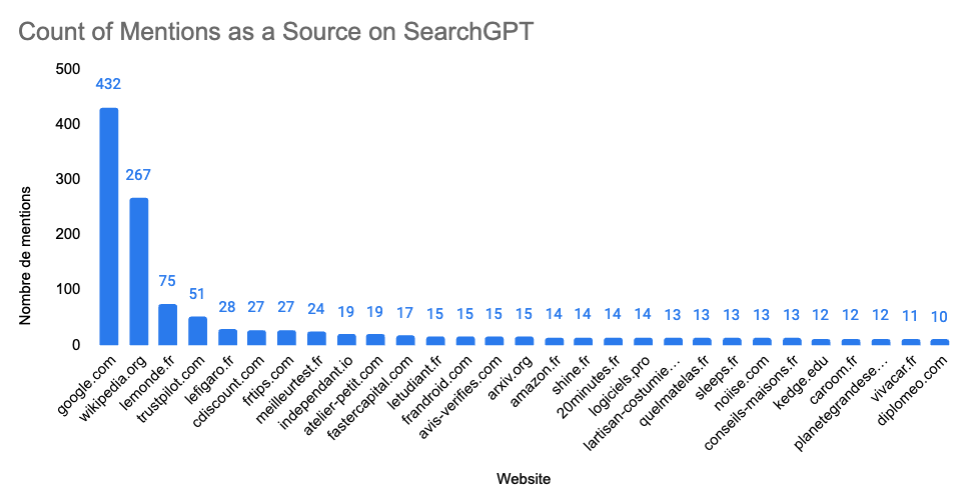
Lemonde is a french newspaper that has a partnership with chat-gpt. Other newspaper like lefigaro or letudiant are very present as sources. Finally SearchGPT loves comparator website like trust pilot or avis verifies. Disclaimer : At the moment we have only 6k sources from SearchGPT. The data is shorter than other LLM as we had some troubles getting the source at the beginning of our usage..
Number of unique domains quoted by SearchGPT : 3557
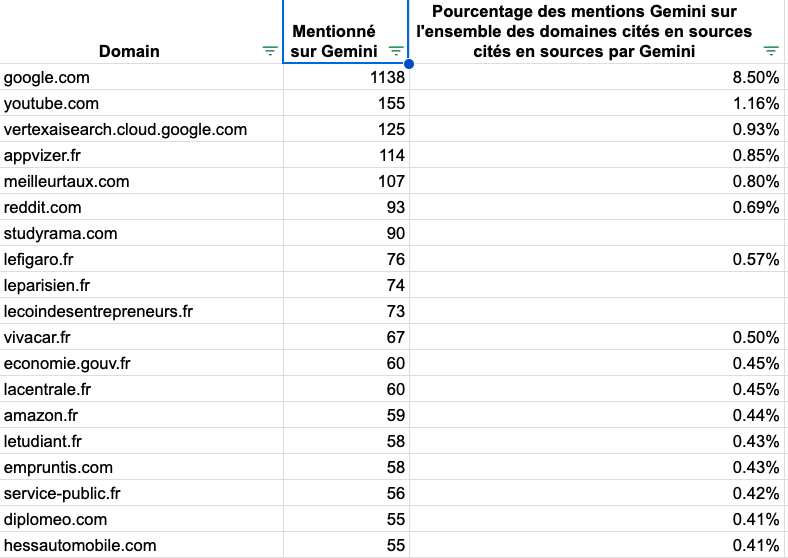
It gets different when you analyze Gemini. 💡 Learnings : First thing, and this is not a big surprise, you can see that most of Google's domains are the most quoted. Google.com are google services. And Youtube belongs to Google in case you forgot. Another difference with SearchGPT is that we see websites from public services in France. Google has always been keen to position those websites well, particularly in the context of YMYL. Finally, you can also see that Reddit is appearing and many other independent media in France. (lecoindesentrepreneurs.fr, studyrama). Those media have worked a lot on their SEO for years, and it seems like it benefits.
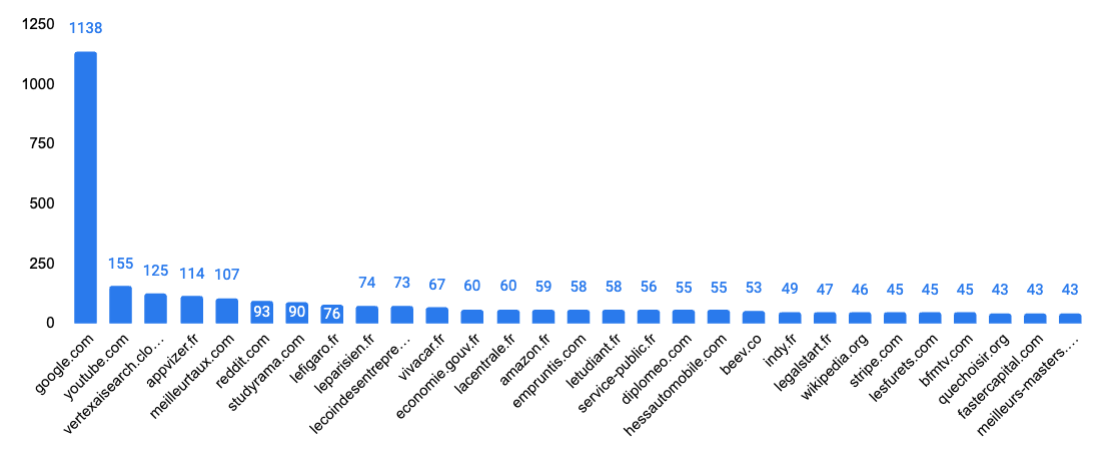
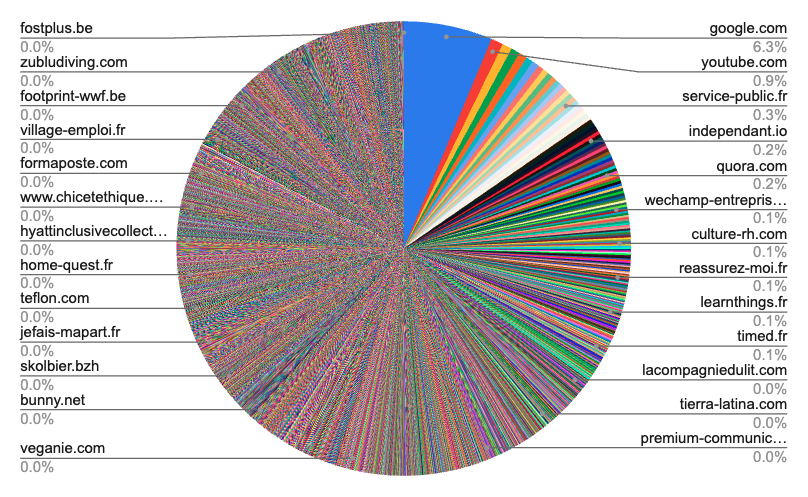
Number of unique domains quoted by Gemini : 13388
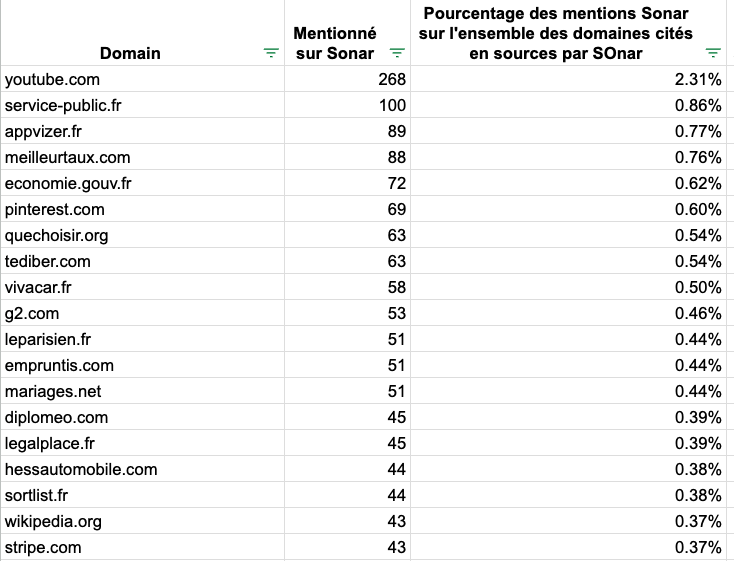
Perplexity is very different in its use of sources. The first thing that we realized is that YouTube is the most used source, so it looks like it likes to show YouTube videos, and if you want to show better in their service, you better go to YouTube as fast as you can. Secondly, we realized that the domains used by Perplexity are more diverse than those of the other models. There isn't a single domain that is used more than the others. Number of unique domains quoted by Sonar : 11591

You might be surprise to see some website you have never heard about before. At url level this can happen if a client adds a very similar query multiple time. Let's imagine an SEO agency in Paris that adds all the following questions on qwairy :
What is the best SEO agency in Paris for Little company
What is the best SEO agency in Paris for Big company
What is the best SEO agency in Paris for Middle company
…
The same source can come back multiple time. We believe we'll be able to show more data for the next analysis we will do next quarter that will contain more data (we aime for at least 100k answers vs 32k for this one). But still this analysis already helps us understand many interesting point. First Wikipedia is coming again many time as a reference.
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
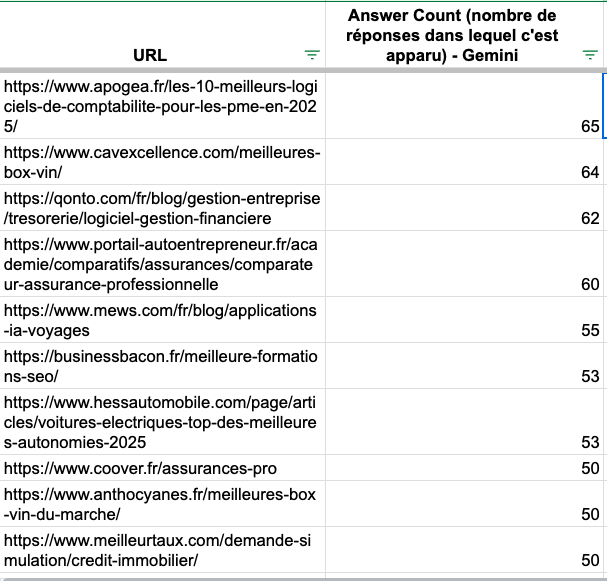
On Gemini sources seems to come from more traditional blog article.
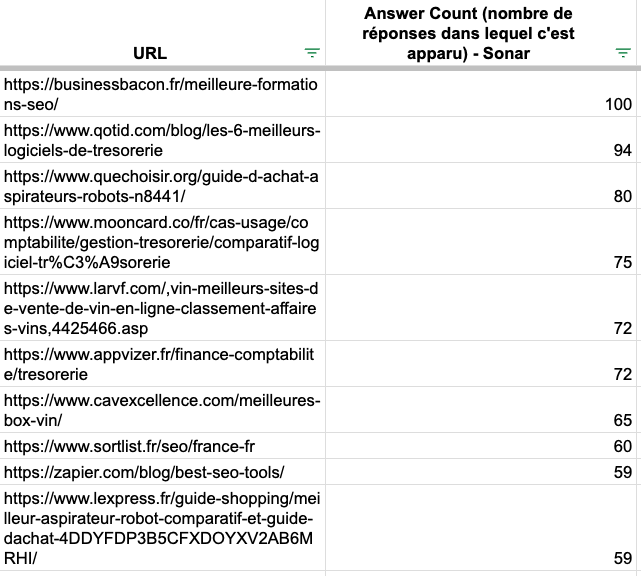
To complete this study we decided to analyse the slug of every url to see which word come the most. Let's start with ChatGPT.
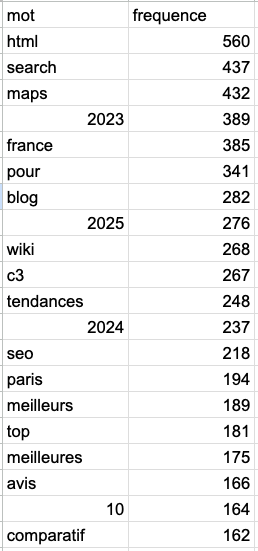
💡 Learnings : Many URLs still contain 2023 in their slug. That's interesting to realize, as most of the models are trained on past data, and it seems like ChatGPT, more than others, is reusing data from 2023. That said it obviously doesn't mean you should add 2023 on your slug to rank as a source on SearchGPT 😅 Finally terms like meilleurs (best), top regularly come back.
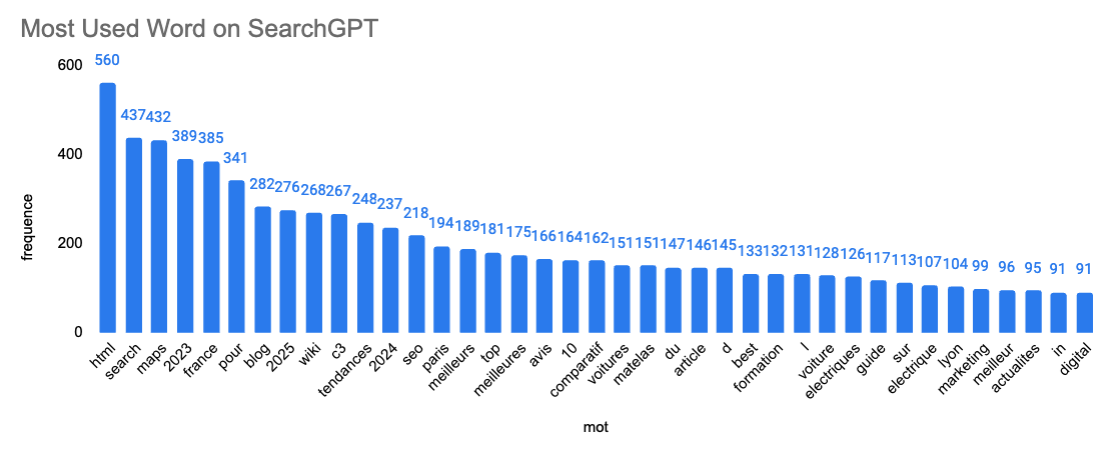
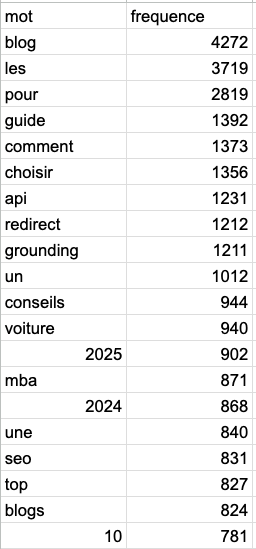
Here the data is slightly different. We can see that Gemini is using more url were the slug contains word like "guide" or "comment" (=how) or even choose.
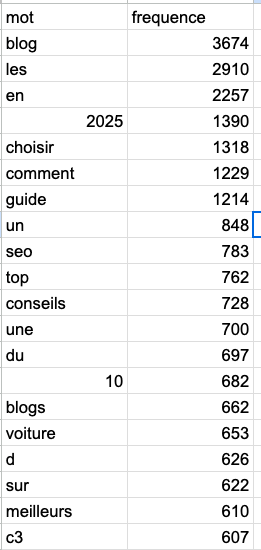
2025 is dominant on Perplexity which might indicate that Perplexity prefers fresh content.
6037 sources (domain) sont utilisés par Sonar et Gemini sur un total de +13k sources 1383 sources sont communes entre chatGPT et Gemini 1321 sources sont communes entre ChatGPT et Sonar sur un total de 2557 sources
With over 32,000 queries analyzed and nearly 60,000 sources examined, this is the most comprehensive study to date on LLM ranking factors. It confirms what many marketers already suspected: Search as we know it is evolving - fast. In this new landscape, engines like SearchGPT, Gemini, and Perplexity no longer return a list of 10 blue links. Instead, they generate direct answers. The game is no longer about ranking high - it's about being mentioned as part of the answer.
Each model behaves differently. Gemini tends to provide longer, more detailed responses. SearchGPT is brief and selective. Perplexity (Sonar) is more varied and diverse in its style.
Tone and structure matter. LLMs rely heavily on impersonal phrasing, conditional forms, imperative verbs, and incentive wording. Mirroring this style in your content may increase your chances of being used as a source.
Formatting is key. Bullet points (using "-") appear in 99% of all responses, showing that LLMs favor clean, well-structured, scannable content.
Specific phrases show up repeatedly - like "by following these steps" or "it is important to." These are simple linguistic cues you can test in your own content.
Source preferences vary by model. ChatGPT leans on authoritative sources like Wikipedia and news sites. Gemini favors Google-owned domains and reliable public sources. Perplexity stands out with more diverse, community-driven content - and a strong use of YouTube.
YouTube is a key channel. Especially for Perplexity, video is a go-to source. If you're not publishing content there, you're likely missing out.
Slug analysis reveals intent signals. Common terms in URLs like "guide", "how", "best", and even dates like "2023" or "2025" suggest that LLMs value timely, practical, and SEO-optimized pages.
LLMs aren't just trying to quote you - they're trying to understand you. That means speaking their language, structuring your content like theirs, and being visible where they source their answers.
For marketers, this opens both opportunities and responsibilities:
Adapt how you write and structure content,
Be present on the platforms and sources LLMs trust,
Think in terms of "being an answer," not just "ranking high."
This study is just the beginning. We plan to update it quarterly with more data and sharper insights. At Qwairy, our mission is to give CMOs, SEOs, and marketing teams the playbook for visibility in the age of Answer Engines.
Track your mentions across ChatGPT, Claude, Perplexity and all major AI platforms. Join 1,500+ brands monitoring their AI presence in real-time.
Free trial • No credit card required • Complete platform access