
We tested the assumption behind Google's "AI optimization is just SEO" guidance: do the domains cited by Google AI match those cited by ChatGPT, Perplexity, Claude and the rest on the same question? They barely do - cross-engine overlap runs 4-19% (Jaccard), and the single top source matches 4-13% of the time. Measured across eight major AI surfaces on production brands, every prompt run repeatedly, over a 90-day window.
In May 2026, Google published guidance telling site owners how to show up in its AI surfaces, AI Overviews and AI Mode, and the headline was reassuring: it comes down to the same fundamentals you already know.
Good content, crawlable pages, the usual SEO hygiene.
The unstated promise underneath it is bigger, and it is the one every marketing team wants to believe: do the work that earns you Google AI visibility, and you have done the work that earns you visibility everywhere - ChatGPT, Perplexity, Claude, the lot.
Other Articles
The ChatGPT Linking Shift, May 2026: Inline Brand Links Jumped 14x in a Single Day
On May 7, 2026, ChatGPT started embedding clickable links to brands' own sites inside its answers. A study of 140,000+ ChatGPT answers: the rate jumped roughly 14× overnight, every link carries a utm_source=chatgpt.com tag, and only ChatGPT moved.
Sources by Intent Study Q2 2026: Brand Editorial Owns 76% of French AI Citations, Wikipedia Barely Makes 3%
A qualitative study on 150 French unbranded prompts across 9 intent typologies. Why brand-owned editorial dominates 76% of AI citations, how negative framing wipes out official sources (×18), and what GEO teams should do about it.
One playbook, every engine.
We can test that promise directly, because it makes a concrete, falsifiable claim: the websites an AI engine cites are its evidence base, and if the playbook is universal, the engines should be drawing on the same evidence. So we asked the simplest possible version of the question.
On the exact same prompt, do two AI engines cite the same domains?
Answer is : They barely do.
Finding #1: cross-engine citation overlap is low.
On the same question, Google AI and ChatGPT cite the same domain only about 7% of the time. Across every pair of engines we measured, overlap runs between 4% and 19%. The single most-cited source - the #1 link - matches between two engines on just 4-13% of questions.
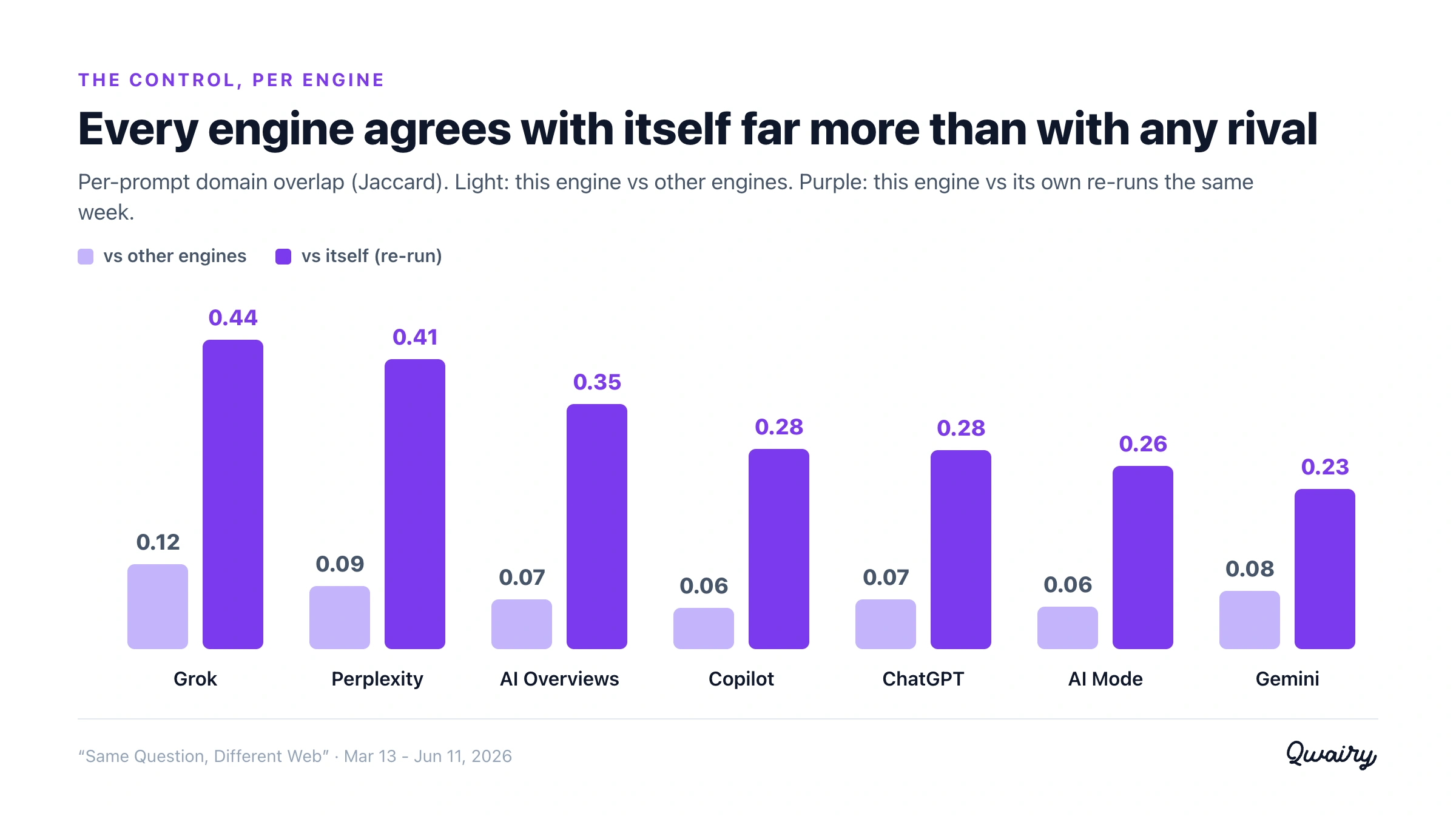
Finding #2 (the control): each engine agrees with itself about 4x more than with any other engine.
The obvious objection to Finding #1 is that AI engines are non-deterministic, so maybe nothing matches anything, including an engine with itself.
So we measured exactly that - the same engine, the same question, two separate runs - and used it as the baseline.
Engines are indeed noisy, but they still cite their own re-runs roughly four times more consistently than they cite alongside a rival.
The cross-engine gap is real signal, not sampling noise.
We measured this across eight major AI surfaces, on production brands we monitor continuously, with every prompt run repeatedly rather than checked once.
The conclusion for anyone doing GEO: there is no single AI search to optimize for. The domains that win you citations in Google AI are mostly not the ones that win you citations in ChatGPT or Perplexity, and "optimize once for all of AI" is not supported by the data.
Engines cite different webs. Per-question overlap of cited domains (Jaccard) runs 4-19% across all engine pairs. Google AI vs ChatGPT: ~7%. Google AI vs Perplexity: ~11%. ChatGPT vs Perplexity: ~7%.
The top source rarely agrees. The #1 cited domain is the same between two engines on only 4-13% of questions. At the level of the exact URL, overlap falls to about 3%.
An engine agrees with itself ~4x more than with any rival. Run-to-run, an engine re-cites 25-57% of its own domains (depending on the engine); across engines it shares only 6-19%. The ratio is about 4x on average, and never below ~2.8x.
Google is two surfaces, not one. AI Overviews and AI Mode - both Google - cite the same source only 19% of the time. That is the highest agreement in the entire study, and it is two Google products disagreeing four times out of five.
The reason is legible: different source diets. Google's surfaces lean on the social web (YouTube, Reddit, Instagram, Facebook, TikTok); ChatGPT leans on Reddit plus the trade and reference press (TechRadar, Wikipedia, arXiv, Forbes, Reuters). Different classes of sources, so different citations.
It holds up. The gap is stable month to month, flat across question intent, identical on English and French prompts for the engine pair measurable in both languages (ChatGPT vs Perplexity), and survives removing the giant platforms (Wikipedia, YouTube, Reddit) entirely.
We measure the domains each engine cites in its answer to a monitored brand's question, deduplicated to the registrable domain (so blog.example.com and example.com count once), and we exclude the brand's own website from every figure - on a brand-monitoring prompt, every engine links the brand itself, and that trivial shared link would only flatter the overlap. Everything below is third-party citations only.
Eight AI surfaces: Google AI Overviews, Google AI Mode, ChatGPT, Perplexity, Claude, Gemini, Microsoft Copilot, xAI Grok - the engines for which we collect source citations.
Unit of analysis: the (question, engine) pair. The same monitored question is answered by every engine, which is what lets us compare citations on a strictly like-for-like basis.
Period: a 90-day window (March 13 to June 11, 2026).
Source: Qwairy Search Intelligence, completed answers only. Each prompt is run repeatedly per engine, which is what makes the self-consistency control possible.
The cohort: questions that were answered, with citations, by ChatGPT and Perplexity and at least one Google AI surface in the window - so every comparison is on prompts all the major engines actually addressed.
We compare which registrable domains each engine cites on the same question.
For each (question, engine) we take the engine's most recent answer in the window as its representative citation set, normalize every host to its registrable domain via the public suffix list, drop the brand's own domain(s), and compute set overlap against the other engines.
We report Jaccard (shared domains / total distinct domains), the asymmetric "share of A's domains also cited by B", and whether the #1-position domain matches. We report rates and ratios, never raw volume counts.
We deliberately do not blend Google's two surfaces into one "Google" number - the whole point is that they differ. We treat AI Overviews and AI Mode separately, and report a fused "Google AI" only as a convenience for the headline pairings.
We also do not lean on a single answer per engine as if it were the truth. AI answers are noisy run to run (we quantify exactly how noisy in Part 2), so a single snapshot would overstate disagreement.
Using each engine's recent representative answer, and validating against each engine's own run-to-run baseline, is what keeps the comparison honest.
Start with the full picture: every engine against every other, on the same prompts.
 Read the off-diagonal cells - two different engines on the same question. They are uniformly low. The most-cited domain pairs barely break 19%; most sit near 7-12%.
Read the off-diagonal cells - two different engines on the same question. They are uniformly low. The most-cited domain pairs barely break 19%; most sit near 7-12%.
Engine pair (third-party domains) | Overlap (Jaccard) | Of A's domains, share also cited by B | Same #1 source |
Google AI vs ChatGPT | ~7% | 13-17% | ~6% |
Google AI vs Perplexity | ~11% | 19-23% | ~6% |
ChatGPT vs Perplexity | ~7% |
A few things stand out. No pair of different engines shares even a fifth of its sources.
The single top citation - the most prominent link in the answer, the one a user is most likely to click - agrees between engines only 4-13% of the time. And at the level of the exact page (not just the domain), overlap collapses to about 3%: even when two engines land on the same site, they usually cite a different article on it.
The asymmetric view adds nuance.
Smaller-diet engines are partly contained by bigger ones - Gemini's sources are 41% a subset of Google AI's, which makes sense for two Google products - but containment is one-directional and never symmetric. No engine is a proxy for another.
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
Here is the objection that could sink the whole study, and the test that answers it. AI engines are non-deterministic: ask twice, get two different answers.
If a single engine disagrees with itself as much as it disagrees with a rival, then Part 1 is just noise and means nothing.
So we measured it.
Because every prompt runs repeatedly, we can take the same engine on the same question across two separate runs and compute the identical third-party domain overlap - one engine versus itself. That is the baseline the cross-engine numbers have to be read against.
 Two honest readings sit side by side here.
First, engines really are noisy.
Two honest readings sit side by side here.
First, engines really are noisy.
Self-consistency tops out around 41% for Perplexity and sits near 28% for ChatGPT - meaning ChatGPT re-cites only about a quarter to a third of the same domains when you ask it the same thing a few days later.
The story is not "engines are deterministic and they disagree." Engines are genuinely unstable, and a single answer should never be read as the truth.
Second, and decisively, self-consistency is far above cross-engine overlap. Every engine re-cites its own sources several times more often than it shares sources with a rival.
Engine | Agrees with itself (same week) | Agrees with other engines | Ratio |
Claude | ~57% | ~11% | ~5.4x |
AI Overviews | ~35% | ~7% | ~4.9x |
Perplexity | ~41% | ~9% |
Note: Claude's cross-engine figures rest on a smaller prompt sample than the other engines and should be read as indicative.
This is the number that defuses the objection. Across the eight engines, an engine agrees with itself about four times more than it agrees with any other engine - and never less than 2.8x.
The cross-engine gap is not the engines being randomly noisy; the noise floor is measured, and the divergence sits four times above it. (We compare like with like: the self-baseline uses re-runs a few days apart, matching the timing of the cross-engine comparison.
Self-consistency decays as runs drift further apart in time, which is exactly why we anchor on the same short window for both.)
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
The single starkest result hides inside Google itself. AI Overviews (the snippet at the top of a results page) and AI Mode (the conversational search experience) are the same company, often the same query - and they agree with each other less than one time in five.
 19% is the highest overlap anywhere in this study - and it is two Google products.
19% is the highest overlap anywhere in this study - and it is two Google products.
Every cross-vendor pair is lower. So a guide that says "optimize for Google's AI" is already ambiguous about which Google it means: a brand can be well-cited in AI Overviews and nearly absent from AI Mode, because the two surfaces are pulling from substantially different source sets.
Treating "Google AI" as one optimization target is a category error before you even get to ChatGPT.
The overlap is low because the engines are not reading the same kind of web. Look at what each one cites most across the shared prompt set.
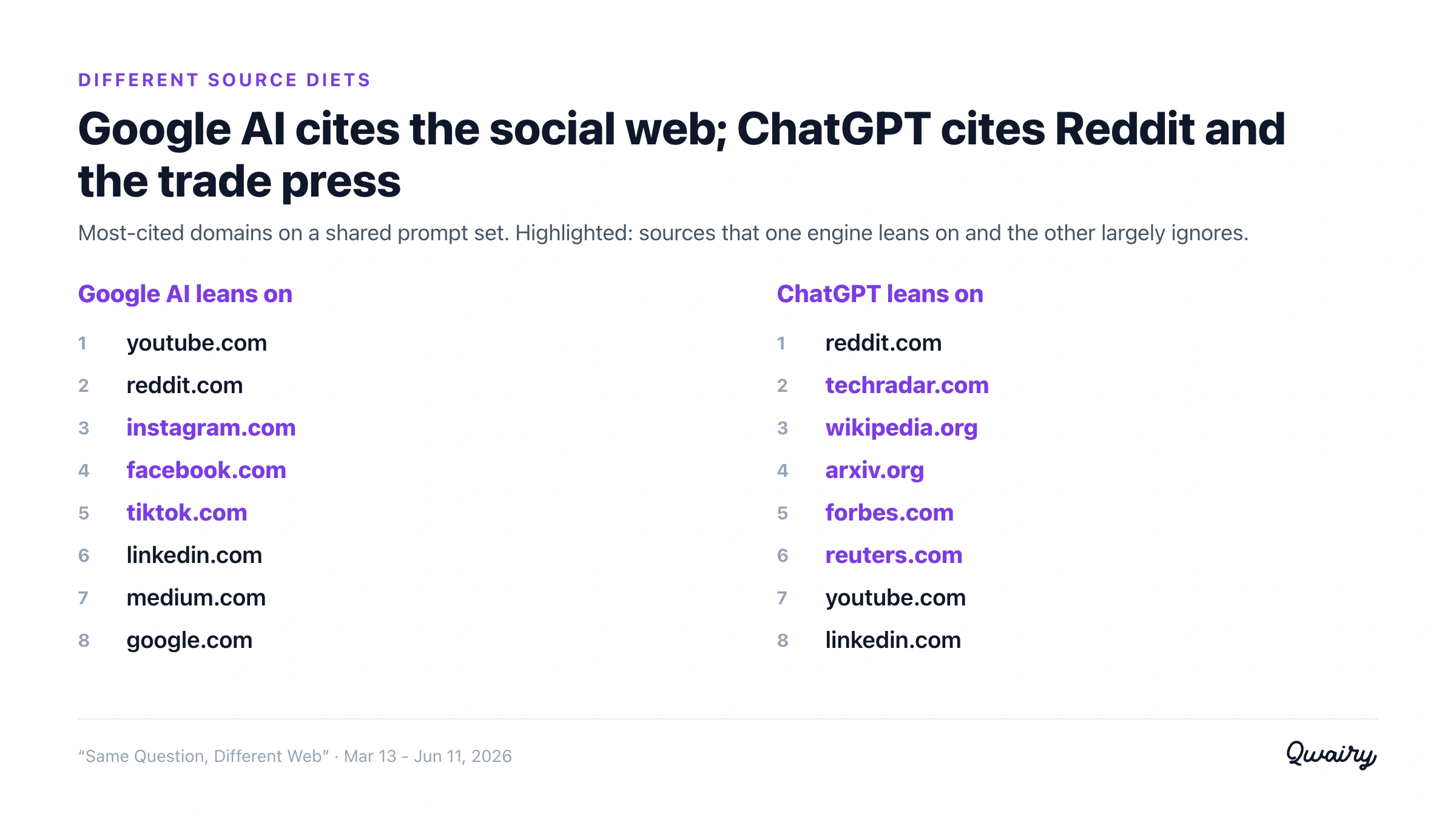
Google's AI surfaces lean on the social web - YouTube, Reddit, Instagram, Facebook, TikTok, LinkedIn. ChatGPT leans on Reddit plus earned editorial and reference - TechRadar, Wikipedia, arXiv, Forbes, Reuters - and cites YouTube a fraction as often as Google does.
Reddit is the one heavy overlap (both lean on it hard), which is precisely why the residual overlap isn't zero. But strip the giant platforms out entirely and the picture barely moves: the divergence is in the long tail of sources too, not just the headline platforms.
This is the mechanism behind every number above.
If your off-site presence is concentrated where one engine looks and thin where another looks, you will win one and lose the other - and no amount of on-page SEO changes which sources an engine reaches for.
There is no "optimize once for all of AI." The domains that earn Google AI citations overlap with ChatGPT's by about 7%. Building for one engine moves the needle on that engine, not on the others. Plan per engine, not for "AI" as a monolith.
Track Google as two surfaces. AI Overviews and AI Mode share 19% of their sources. Blend them into one "Google AI" score and you will miss real movement on each. They are two channels.
Match your off-site work to each engine's diet. Google's surfaces reward a strong social and community footprint (YouTube, Reddit, Instagram); ChatGPT rewards Reddit plus earned press and reference coverage. The source families differ, so the earned-media plan differs.
Measure citation share per engine, not blended. A single "AI sources" report averages away the fact that you are winning one engine and losing another. Break it out by engine, and by Google surface.
Never trust a single check. Engines re-cite only a quarter to a half of their own sources run to run. One answer is one draw from a noisy distribution. Read citation rates over many runs, or you are reacting to noise.
Reality: the domains Google AI cites overlap with ChatGPT's by about 7% on the same question. SEO fundamentals may help you get crawled everywhere, but which sources each engine reaches for differs sharply. One source-building playbook does not transfer across engines.
Reality: cross-engine citation overlap runs 4-19%, and the top source matches 4-13% of the time. Presence in one engine is weak evidence of presence in another.
Reality: AI Overviews and AI Mode agree with each other only 19% of the time - the highest agreement in the study, and it is two Google products. Optimize for each surface.
Reality: each engine agrees with its own re-runs about 4x more than with any other engine. The randomness is real and measured, and the cross-engine divergence sits four times above it. The gap is structural.
Scope: eight AI surfaces - Google AI Overviews, Google AI Mode, ChatGPT, Perplexity, Claude, Gemini, Microsoft Copilot, xAI Grok - measured on production client brands over a 90-day window (March 13 to June 11, 2026; audit and test brands excluded). Every prompt is run repeatedly per engine, which is what enables the self-consistency control.
Methodology: quantitative analysis of the source citations in completed AI answers. For each (question, engine) we take the engine's most recent answer as its representative citation set, normalize every cited host to its registrable domain (eTLD+1) via the public suffix list, exclude the monitored brand's own domain(s), and compute set overlap against other engines: Jaccard (shared / total distinct domains), asymmetric containment, and top-1 (position-1 domain) agreement. The cohort is questions answered with citations by ChatGPT, Perplexity and at least one Google AI surface in the window. Self-consistency uses prompts with two or more answers per engine: consecutive answers are paired and the same third-party overlap is computed, bucketed by the time gap between runs.
Non-determinism is measured, not eliminated. Self-consistency is well below 100% (about 25-57% depending on engine). We quantify the noise floor and show the cross-engine gap sits ~4x above it; we do not claim engines are stable.
Registrable-domain grain. We count a source as shared if the engines cite the same registrable domain, which merges subdomains. At the exact-URL level overlap is even lower (~3%), so this choice is conservative - it makes the engines look more alike than they are.
Citation cardinality varies by engine. Some engines cite many more domains per answer than others. Raw Jaccard penalizes uneven set sizes; we re-checked with a size-normalized variant (cutting both sets to the same top-k) and the ranking holds.
Timing. Cross-engine answers are not always captured at the same instant; restricting to answer pairs within two weeks of each other does not change the result.
Monitored-brand population. These are brands actively tracked by their owners, not a neutral sample. The comparison controls for this because all engines see the same brands and prompts.
Snapshot. This is a 90-day window. AI surfaces evolve quickly; a repeat next quarter may move.
All figures are relative measures - rates, ratios, per-answer overlap - never raw volume counts.
The monitored brand's own domain is excluded from every overlap figure, so the numbers reflect third-party citations only and are not inflated by the trivial self-link every engine includes.
We report each engine's own run-to-run self-consistency as the baseline, so the cross-engine overlap is interpreted against the measured noise floor rather than against an assumption of determinism.
Google Search Central, Optimizing your website for generative AI features on Google Search (May 2026) and the announcement post A new resource for optimizing for generative AI in Google Search (May 15, 2026)
Related research: The Two Blind Spots in AI Visibility, The ChatGPT Linking Shift
New to the topic? Start with What is GEO?
Want to see which sources each AI engine cites for your brand, per engine and per Google surface, measured over repeated runs instead of one-off checks? Qwairy tracks brand mentions, position and citations across AI Overviews, AI Mode, ChatGPT, Perplexity, Claude, Gemini and expanding providers, with per-engine source analytics.
Track your mentions across ChatGPT, Claude, Perplexity and all major AI platforms. Join 1,500+ brands monitoring their AI presence in real-time.
Free trial • No credit card required • Complete platform access
~4% |
Google AI vs Gemini | ~11% | Gemini's sources are 41% inside Google AI's | — |
AI Overviews vs AI Mode (both Google) | ~19% (the maximum) | 28-38% | ~13% |
Whole-matrix range | 4% to 19% | - | 4-13% |
~4.6x |
Copilot | ~28% | ~6% | ~4.8x |
ChatGPT | ~28% | ~7% | ~4.0x |
AI Mode | ~26% | ~6% | ~4.3x |
Grok | ~44% | ~12% | ~3.7x |
Gemini | ~23% | ~8% | ~2.8x |
Average | ~4x |