We measured how AI engines END their answers on the commercial questions brands compete on: how often the engine closes by offering to keep going ("If you want, I can narrow this down by budget, region, use case"). Measured across the major AI engines we monitor over a 90-day window.
For most of the search era, an answer was a destination.
You asked, you got a result, the interaction ended.
AI assistants quietly changed that. Increasingly, the answer is not where the conversation stops - it is where the engine tries to start the next one.
You have seen the move even if you never named it.
ChatGPT finishes a recommendation and adds: "If you want, I can narrow this down based on your budget, your region, and how you'll use it."
Often it is not even a sentence - it is a little menu of next steps. That closing line is deliberate: it reopens a question you might have considered closed.
We can measure how common this has become, because the closing of an answer is observable. So we asked the simple version:
Other Articles
Same Question, Different Web: AI Engines Barely Cite the Same Sources (June 2026)
We tested the assumption behind Google's "AI optimization is just SEO" guidance: do the domains cited by Google AI match those cited by ChatGPT, Perplexity, Claude and the rest on the same question? They barely do - cross-engine overlap runs 4-19% (Jaccard), and the single top source matches 4-13% of the time. Measured across eight major AI surfaces on production brands, every prompt run repeatedly, over a 90-day window.
The ChatGPT Linking Shift, May 2026: Inline Brand Links Jumped 14x in a Single Day
On May 7, 2026, ChatGPT started embedding clickable links to brands' own sites inside its answers. A study of 140,000+ ChatGPT answers: the rate jumped roughly 14× overnight, every link carries a utm_source=chatgpt.com tag, and only ChatGPT moved.
The answer is: far more than you would guess, and they differ enormously.
Finding #1: on commercial questions, the follow-up is now the norm, not the exception.
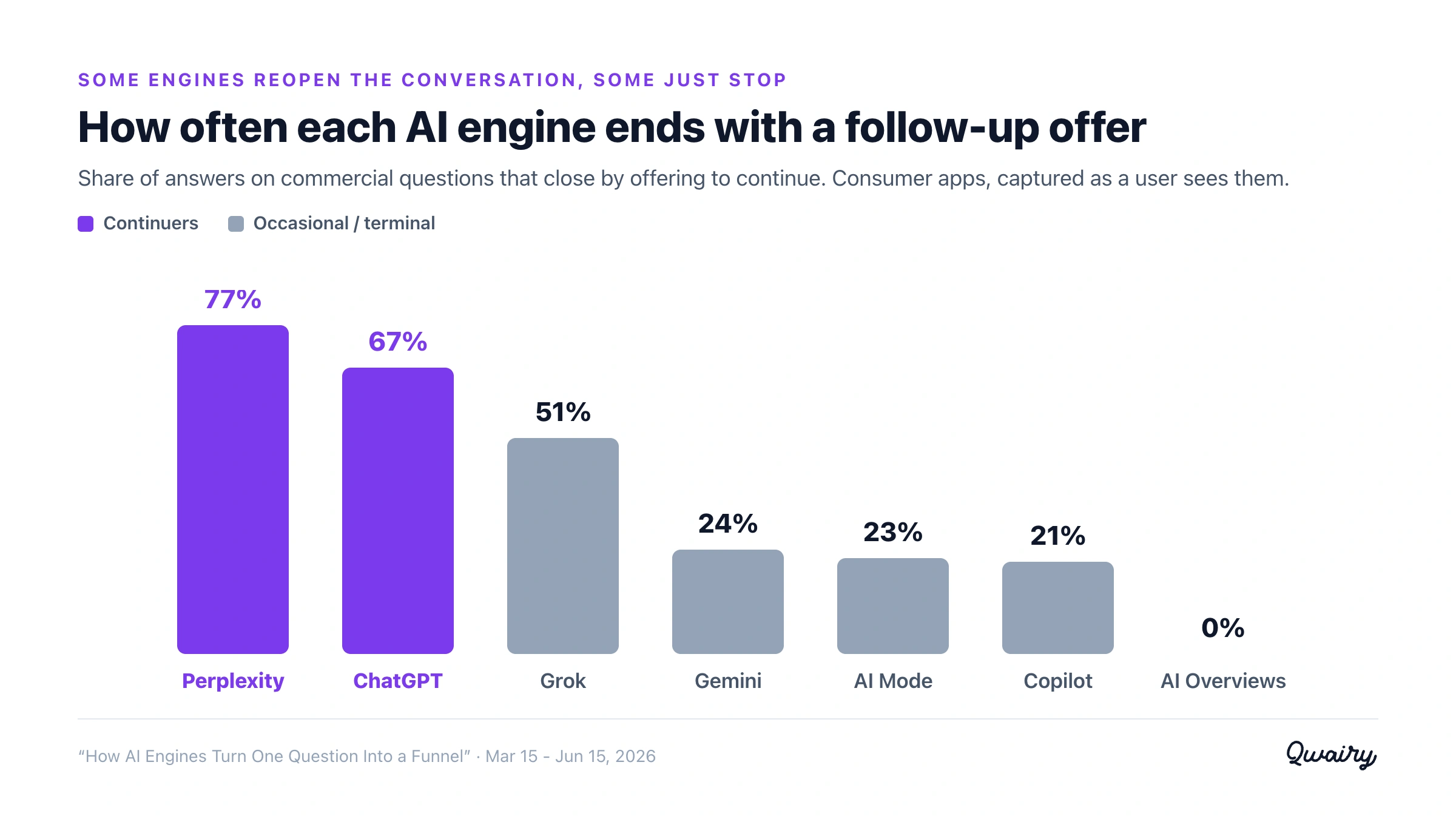
On the recommendation, comparison and how-to questions that decide whether a brand gets surfaced, ChatGPT ends about two of every three answers with an offer to continue. Eight months ago it was about one in three. The behavior roughly doubled.
Finding #2: this is a spectrum, not a fact about "AI."
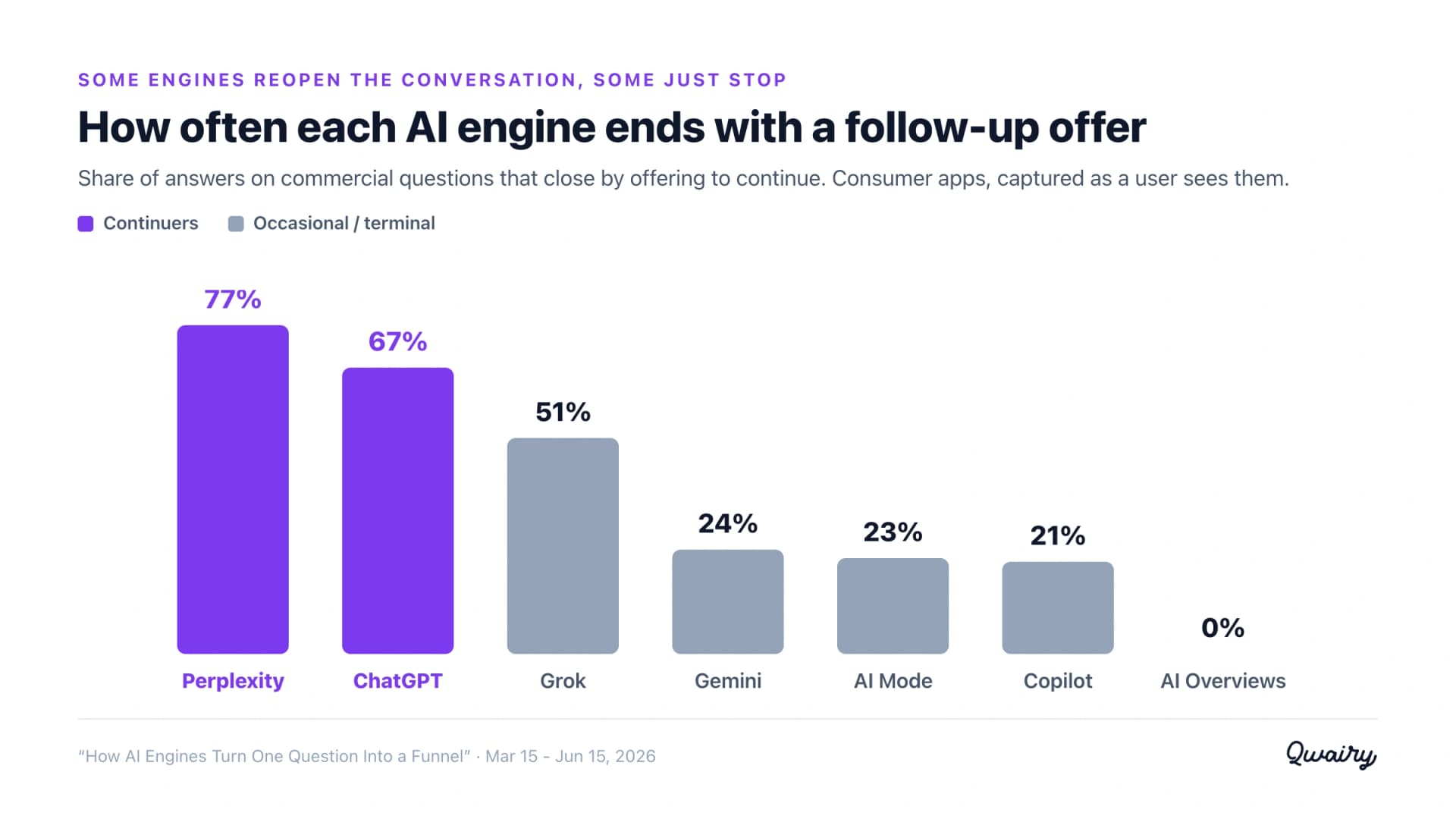
Among the consumer assistants, Perplexity (~77%) and ChatGPT (~67%) turn most answers into an opening, while Google's AI Overviews (~0%) and Gemini (~24%) mostly answer and stop. The engines people use for open-ended discovery are the ones most aggressively reopening the conversation.
The strategic point underneath both findings is the one that matters for visibility: the first answer is no longer the whole game. It is increasingly the top of a funnel the engine opens itself - and because chat models condition on the prior turn, the brands named in that first answer are largely the ones that carry into it, which we measure directly below.
The follow-up offer is now the default close on commercial queries. ChatGPT ends ~67% of answers with one across the 90-day window; on guide and how-to questions it reaches ~78%.
It roughly doubled in eight months. ChatGPT's rate climbed from about a third of answers in late 2025 to about two-thirds by mid-2026.
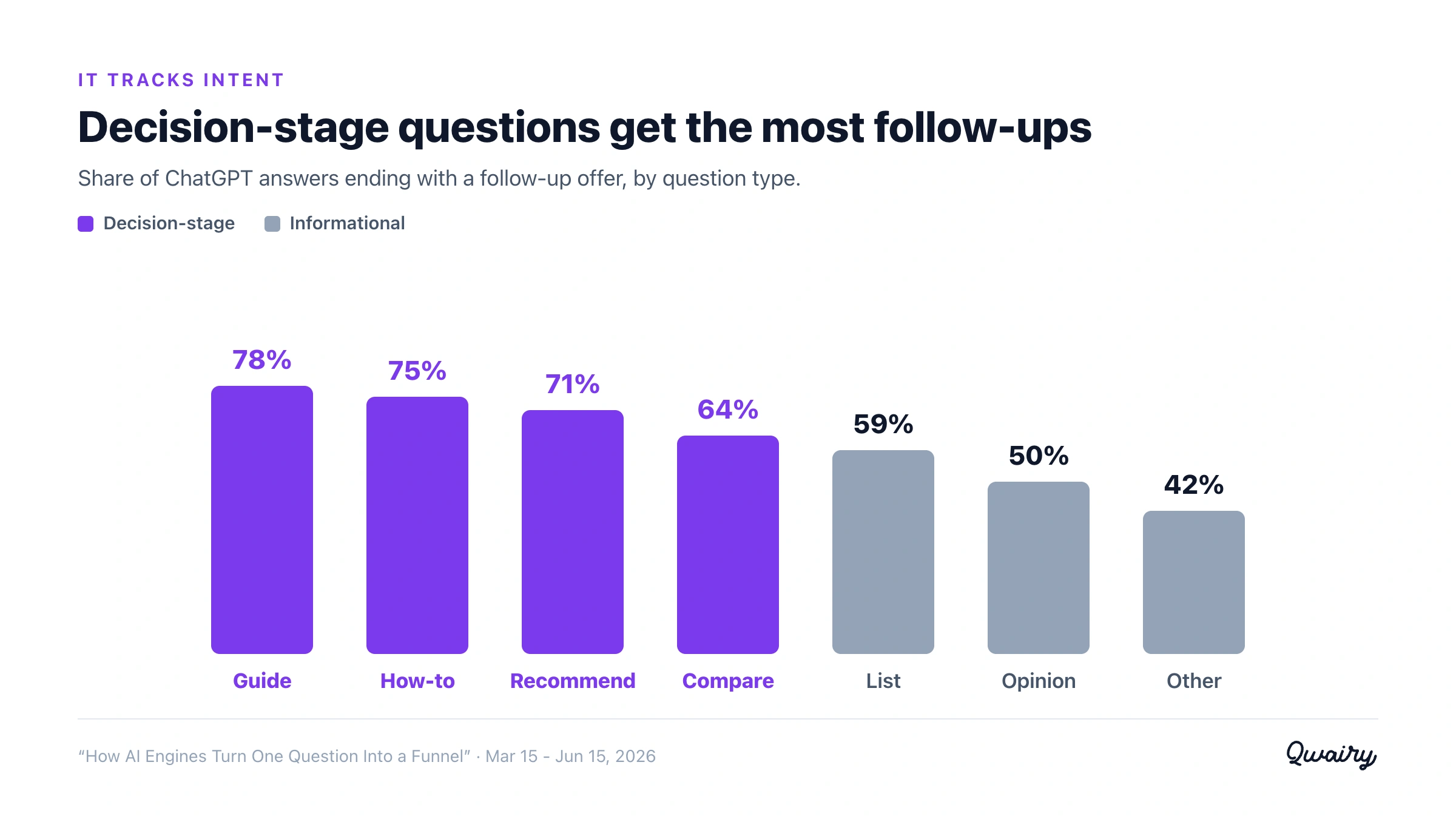
It tracks intent. The rate is highest on action-oriented questions (guide ~78%, how-to ~75%, recommendation ~71%) and lowest on opinion (~50%) and miscellaneous (~42%). The more a question looks like a decision, the more the engine offers to help you make it.
The dominant move is "narrow it down." ~9 in 10 of ChatGPT's follow-ups are a conditional refine - "if you tell me your budget / region / use case, I can…" - and ~73% of them are formatted as a bullet menu rather than a sentence.
Engines occupy a spectrum. Continuers: Perplexity ~77%, ChatGPT ~67%, Mistral ~55%, Grok ~51%. Occasional: Gemini ~24%, Google AI Mode ~23%, Copilot ~21%. Terminal: Google AI Overviews ~0%. (Claude, which we access via API rather than its consumer app, sits at ~7% - see methodology.)
The phrasing differs by engine. ChatGPT and Perplexity offer to refine; Grok and Mistral offer to do more directly ("I can also…"); Gemini, when it engages, mostly asks a yes/no question ("Would you like me to…"); Copilot sometimes offers explicit choice chips.
A closing offer is counted only when it appears in the final stretch of the answer (the last ~15%), so we measure how an engine ends, not stray "I can" phrasing mid-text. Everything below is rates across many answers, never raw volume.
Scope. The major AI engines we monitor: ChatGPT, Perplexity, Google Gemini, Microsoft Copilot, xAI Grok, Google AI Overviews, Google AI Mode, Anthropic Claude, Mistral and DeepSeek.
A 90-day window (mid-March to mid-June 2026), completed answers only, brands monitored on the platform.
The unit of analysis is the individual answer, and we look at how it ends.
How we capture each engine (this matters). We capture most engines through their consumer product - ChatGPT, Perplexity, Gemini, Copilot, Grok and Google's AI Overviews and AI Mode are collected as a user would see them. A few (Claude, GPT via API, Mistral, DeepSeek) are accessed via API.
The follow-up offer is largely a product-layer behavior - a choice baked into the consumer app's instructions and tuning, not the raw model - so an API-accessed engine shows far less of it than its consumer app would.
Claude's ~7% is therefore a floor, not a verdict on Claude's consumer app; the clean apples-to-apples comparison is among the consumer products, which is where we anchor the spectrum.
What we measure, and what we deliberately do not. We classify whether the closing of an answer (the final ~15% of the text) contains a follow-up offer: a phrase proposing a next step - to refine, expand, compare, or do more - in English or French, the two languages that dominate the set.
We bucket each into a family: conditional-refine ("if you tell me X, I can…"), direct-offer ("I can also…"), question-offer ("would you like me to…"), passive ("let me know if…"), and flag whether the close is a bullet menu.
We do not read a single answer as the truth about an engine (we measure across many and report rates), we do not report raw volumes, and we confine the detector to the closing of the answer.
Start with ChatGPT, the engine most people picture when they say "AI search."
Across the window, about 67% of its answers end with a follow-up offer - and it is not static.
Tracked month over month, the rate climbed from roughly a third of answers in late 2025 to roughly two-thirds by mid-2026. It about doubled in eight months.
 The headline number understates the experience, because the rate is not even - it concentrates exactly where brands compete.
The headline number understates the experience, because the rate is not even - it concentrates exactly where brands compete.
The follow-up is not sprinkled evenly across questions. It tracks how much the question looks like a decision.
Question type | ChatGPT answers ending with a follow-up |
Guide | ~78% |
How-to | ~75% |
Recommendation | ~71% |
Comparison | ~64% |
List | ~59% |
Opinion |
Ask "what is X" and you are less likely to get an offer to continue.
Ask "which X should I pick" or "how do I do X" - the questions where a brand can be recommended - and the engine almost always offers to take you further. The follow-up is densest precisely on the commercial, consideration-stage queries that GEO is about.
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
Nine in ten of ChatGPT's follow-ups are the same move: a conditional refine.
The engine offers to personalize its answer if you hand over a few more details, and it usually lays those details out as a menu. A representative close:
If you tell me:
your provider,
your region,
whether you're switching plans or moving,
…then I can give you the exact procedure and any fees that apply.
About 73% of ChatGPT's follow-ups are formatted as a bullet menu like this, not a sentence. That formatting choice is quietly important for visibility: the menu is a map of the dimensions the engine thinks matter for the decision - budget, region, use case, size.
Those are the sub-queries the refined turn will be built on.

Here is where "AI does X" falls apart. Among the consumer assistants - captured exactly as a user sees them - the behavior is a spectrum, and the engines sit at very different points on it.
Engine (as captured) | Ends with a follow-up | Signature move | Bullet menu |
Perplexity (consumer) | ~77% | conditional refine | 28% |
ChatGPT (consumer) | ~67% | conditional refine | 73% |
Mistral (API) | ~55% |
Clear clusters fall out.
The continuers: Perplexity and ChatGPT.
Despite being an "answer engine," Perplexity closes with a follow-up more often than ChatGPT - usually an inline offer rather than a bullet menu: "If you tell me your goal and your current training level, I can build you a simple, tailored plan and estimate a target calorie intake." ChatGPT prefers the bullet menu. Both treat the answer as a first move.
The direct-offerers: Grok and Mistral. These offer to do more rather than ask you to specify, often with an exclamation point: "If you tell me your region and sector, I can refine these recommendations with more targeted contacts!"
Gemini, the question-asker. Gemini engages on only about a quarter of answers, and when it does, ~79% of the time it is a closed question rather than a refine menu: "Would you like me to compare the warranty options for a specific insurer?" The rest of the time it simply ends.
Copilot, the chip-offerer. When Copilot continues, it often presents explicit choices: "Would you like me to compare the two models directly, or show available listings in your area? Compare models / Show local listings."
The terminal end: AI Overviews (and, as we capture it, Claude).
Google's AI Overviews effectively never offer a follow-up (~0%): it is a static snippet, not a conversation, so there is no next turn to open.
Claude, accessed via API, ends with a follow-up only ~7% of the time - it tends to deliver a complete answer and stop on a declarative line. (Because this is the API and not the consumer Claude app, treat ~7% as a floor.)
The pattern worth sitting with: the engines doing this most are the ones people actually use for open-ended discovery.
The conversational front doors to AI - ChatGPT and Perplexity - are exactly the ones turning a single question into a multi-step funnel.
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
Everything above measures how answers end.
The strategic claim - that the brands named in the first answer carry into the refined turn - is a separate question, and our monitoring corpus cannot answer it, because it is single-turn. So we built the missing turn.
We ran 80 commercial questions through a chat model (gpt-5) as real two-turn conversations.
Turn 1: the question. Turn 2: accept the follow-up and ask it to narrow to a top three.
Against that, a cold control: the same refined ask with no history - a fresh model, no first answer to lean on.
The test: does the continued conversation's shortlist draw on the first answer's brands more than the cold one does?
It does, with a clear boundary.
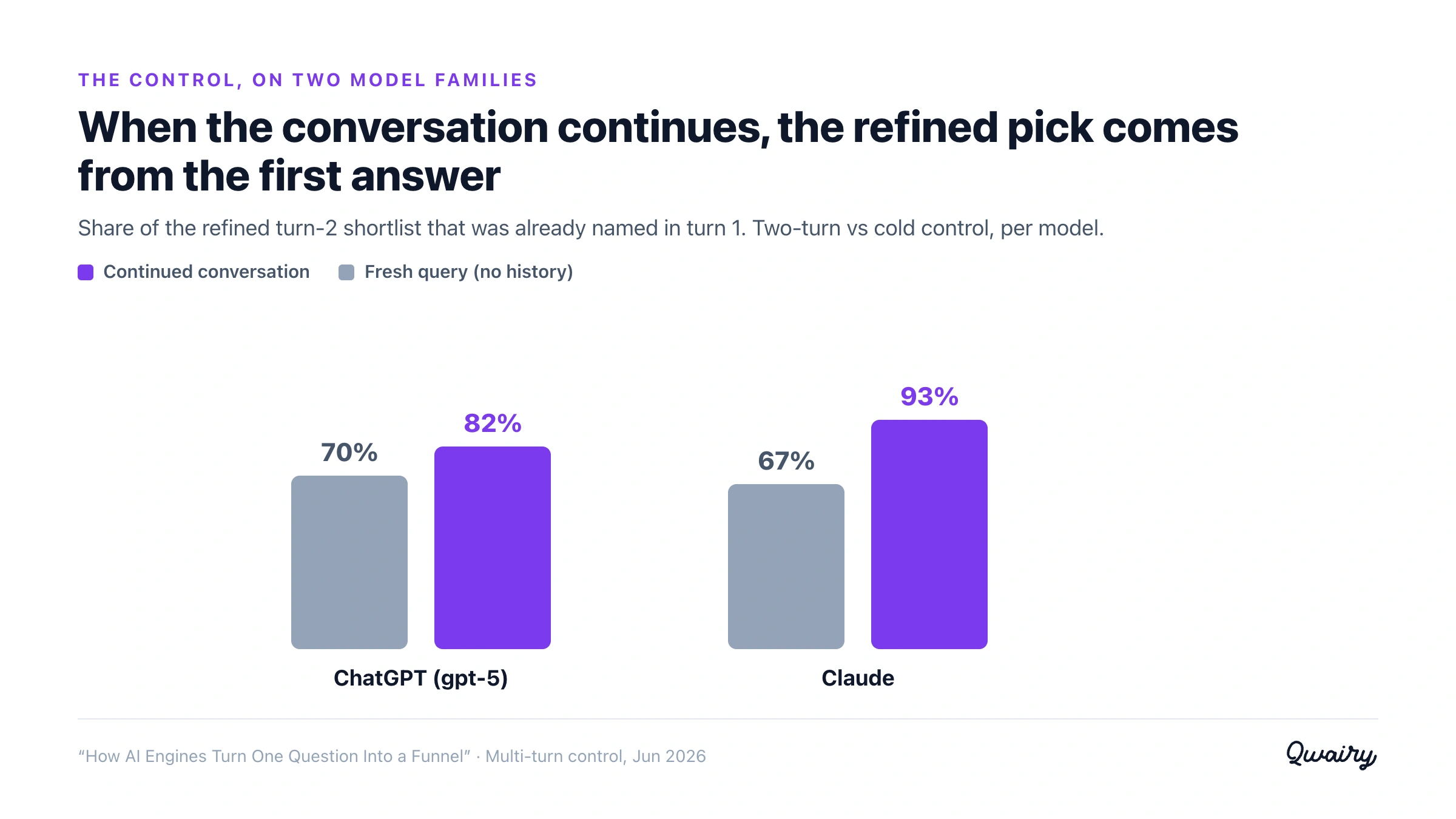
The continued conversation's shortlist is ~82% drawn from the first answer's brands; a cold query draws ~70% from that same set. Carryover adds about +12 points on average.
Where it was decisive, it broke about 4 to 1 for the first answer. In the 41 questions where the two turns disagreed at all, the continued conversation favored the first answer's brands in 33, the cold control in only 8. The other 39 were ties - consensus categories where the same leaders win regardless of history.
Read it as the cost of absence. A fresh query surfaces a brand that was not in the first answer about 30% of the time; the continued conversation, about 18%. Once the conversation is underway, the door to a new brand is roughly 40% narrower.
So the funnel is real, and bounded.
In consensus categories - one dominant set of leaders - it barely matters; you would be named either way.
In fragmented, competitive categories - exactly where a challenger has something to win or lose - the first answer largely is the refined answer, and the refinement rarely lets a newcomer back in.
It holds across model families. We re-ran the control on a second model (Claude) and the carryover was, if anything, stronger: the continued conversation's shortlist was ~93% drawn from the first answer versus ~67% cold - a +26-point effect that favored the first answer 11 to 1 on the questions where the two turns disagreed.
Tellingly, that same model offers a follow-up on its own only ~13% of the time, in line with its terminal profile above.
That separates the two things cleanly: whether an engine reopens the conversation is a product choice, but once it is reopened, the prior turn's brands carry forward either way.
Two honest limits. We tested the mechanism through model APIs, not the consumer apps, so this is about how a chat model conditions on its own prior turn - fundamental rather than product-specific.
And the effect (+12 to +26 points across the two models) is conservative: it is pulled toward zero by the consensus categories that tie at the top. (As a bonus check, gpt-5 closed 63% of these first-turn answers with a follow-up on its own - in line with the ~67% we measure in the wild.)
Win the first answer, because it seeds the second. When a user accepts a follow-up, the refined turn draws ~82% of its picks from the first answer's brands, versus ~70% for a cold query with no history (see Part 5).
Being in the initial answer is no longer just one impression - it is your ticket into the refined turn, and a brand absent from it rarely gets back in. Optimize for presence on the broad, commercial query, not only the long-tail one.
Read the menu as a keyword map. The dimensions an engine offers to "narrow by" - budget, region, use case, size - are the sub-queries the next turn will run. They tell you, per category, which qualified variants ("best X under a budget", "best X for a use case", "X in a region") you also need to be present on.
Plan per engine, not for "AI." A follow-up-heavy engine (ChatGPT, Perplexity) rewards content that maps cleanly to refine-by dimensions and recombines across turns. A terminal surface (AI Overviews) rewards a single, complete, well-cited answer because there is no second turn to win. The same content strategy does not serve both.
Track the closing, not just the body. Whether and how an engine offers to continue is itself a signal that moves over time - ChatGPT's rate doubled in eight months. It changes how users journey from question to choice, and it is worth monitoring as its own metric, per engine.
Reality: on the most-used consumer engines, two to three of every four answers end with an offer to continue, and when the conversation continues the refined pick is ~82% drawn from the first answer (versus ~70% for a cold query - see Part 5).
Reality: among consumer products, the follow-up rate ranges from ~0% (Google AI Overviews) to ~77% (Perplexity) on the same kinds of questions. One surface answers and stops; another reopens almost every time. "AI" is not one behavior.
Reality: the bullet menu is a map of the decision dimensions the engine will use to refine - budget, region, use case. It tells you which qualified sub-queries you also need to win.
Reality: we measure on the commercial, brand-relevant questions, and the rate varies by intent from ~42% to ~78%. This is the rate on the questions that decide visibility, not a claim about every ChatGPT conversation.
Scope: the major AI engines monitored on Qwairy - ChatGPT, Perplexity, Google Gemini, Microsoft Copilot, xAI Grok, Google AI Overviews, Google AI Mode, Anthropic Claude, Mistral and DeepSeek - over a 90-day window (mid-March to mid-June 2026), completed answers only. ChatGPT's month-over-month trend uses a longer window back to late 2025.
Methodology: we classify the closing of each answer (the final ~15% of the text) for a follow-up offer - a phrase proposing a next step (refine, expand, compare, do more), detected in English and French, the two dominant languages in the set. Each follow-up is bucketed into one family - conditional-refine, direct-offer, question-offer, passive - by priority, and flagged as a bullet menu when the close contains two or more list items. We report rates across many answers per engine; figures are rounded. Most engines are captured through their consumer product; Claude, GPT-API, Mistral and DeepSeek are accessed via API.
Consumer product vs API. The follow-up is largely a product-layer behavior. Engines captured via their consumer app (ChatGPT, Perplexity, Gemini, Copilot, Grok, Google's surfaces) are comparable to each other; API-accessed engines (Claude, Mistral, DeepSeek, GPT-API) undercount what their consumer apps do. We anchor the cross-engine spectrum on the consumer products.
Heuristic detection. Follow-ups are identified by phrase patterns at the close, tuned for English and French. Phrasing the patterns miss is undercounted, so absolute rates are best read as a floor; the cross-engine ranking among comparable captures is the robust result.
Captured text includes some chrome. For a few engines the scraped answer carries interface elements (e.g. citation rows); this can dilute the measured rate slightly.
Intent labels (guide, how-to, recommendation…) are model-assigned and approximate.
Snapshot. A 90-day window. AI surfaces change fast - providers have shipped changes aimed at this exact behavior - so a repeat next quarter may move.
Single-turn monitoring, plus a multi-turn control. Our monitoring corpus is single-turn; to test whether turn-1 brands carry into an accepted follow-up we ran a separate two-turn experiment (Part 5). Those controls use model APIs rather than the consumer apps, so they measure the carryover mechanism, not the exact consumer product.
Monitored-brand population. These are brands tracked by their owners, not a neutral sample. The cross-engine comparison controls for this because every engine sees the same brands and prompts.
Headline figures are relative measures - rates and ratios; we do not publish raw monitoring volumes (answers or prompts tracked). The multi-turn control (Part 5) reports its own sample size and counts, as an experiment should.
The detector reads only the closing of each answer, so figures describe how engines end, not overall phrasing frequency.
Quoted closings are representative, lightly edited for length and to remove specific brand names; rates are computed across many answers to average out run-to-run noise.
New to the topic? Start with What is GEO?
Related research: AI Engines Barely Cite the Same Sources, The Two Blind Spots in AI Visibility
Want to see how each AI engine ends its answers about your brand - whether it reopens the conversation, and with which refine-by dimensions, measured across repeated runs instead of one-off checks? Qwairy tracks brand mentions, position, citations and answer behavior across ChatGPT, Perplexity, Google AI, Claude, Gemini and expanding providers.
Track your mentions across ChatGPT, Claude, Perplexity and all major AI platforms. Join 1,500+ brands monitoring their AI presence in real-time.
Free trial • No credit card required • Complete platform access
Other | ~42% |
86% |
Grok (consumer) | ~51% | direct offer | 52% |
Gemini (consumer) | ~24% | yes/no question | 15% |
Google AI Mode (consumer) | ~23% | mixed | 55% |
Copilot (consumer) | ~21% | mixed / choice chips | 56% |
DeepSeek (API) | ~12% | mixed | 52% |
Claude (API) | ~7% | rarely engages | 27% |
Google AI Overviews (consumer) | ~0% | never | - |