A qualitative study on 150 French unbranded prompts across 9 intent typologies. Why brand-owned editorial dominates 76% of AI citations, how negative framing wipes out official sources (×18), and what GEO teams should do about it.
What we found across 150 French prompts answered by ChatGPT (Core) and Perplexity:
Brand-owned editorial content owns 76% of citations on average, peaking at 89% on local-intent prompts. Wikipedia maxes out at 2.7% on definition prompts, and press media never exceeds 2% on any intent type we tested.
Intent dictates the source landscape. Official portals (.gouv.fr and regulators) carry 28% of citations on tutorial prompts and 20% on legal prompts, and exactly 0% on open-recommendation prompts. Aggregators and forums emerge specifically on commercial recommendation queries.
Negative framing divides official-source citations by ~18. On the same Reliability topic, rephrasing a question into a critical register ("why is X criticized") collapses the share of institutional sources from 11.1% to 0.6%, while community forums double their share.
ChatGPT and Perplexity are not interchangeable retrieval systems. At comparable citation depth (~8-10 sources per sourced answer), ChatGPT cites community forums roughly 11× more than Perplexity, and twice as many institutional sources. Perplexity cites video and aggregators more heavily.
Methodological filter applied throughout the paper. Answers that contain zero citations are excluded from analysis. The binary "to cite or not to cite" decision is a legitimate but distinct dimension that would conflate two signals into a single metric. The study focuses exclusively on the sourcing profile observed when the assistant decides to cite. Out of 600 generated answers, 430 are retained.
What this paper deliberately does not cover. Gemini, Claude, Mistral, and DeepSeek are out of scope for this iteration, instrumentation for our internal stable extraction pipeline is incomplete on those providers. We address what their inclusion would change in Part 9 and outline the Q3 2026 plan.
Other Articles
How Qwairy Predicts the 2026 World Cup Winner
A Qwairy research study on how AI answer engines frame the 2026 World Cup winner, where they agree, where answers become volatile, and what marketers can learn from AI perception mapping.
The Answer Is Now an Opening: How AI Engines Turn One Question Into a Funnel (June 2026)
We measured how AI engines END their answers on the commercial questions brands compete on: how often the engine closes by offering to keep going ("If you want, I can narrow this down by budget, region, use case"). Measured across the major AI engines we monitor over a 90-day window.
The single most repeatable finding in this study is also the one most likely to reshape French GEO strategy in 2026: on every intent type we measured, the largest source family, by a wide margin, is content published by economic actors themselves.
We grouped 1,819 distinct cited domains into nine generic families (taxonomy detailed in Part 2). One family alone, brand-owned editorial & SEO publishers, which includes consulting firms, SaaS platforms, corporate editorial blogs, brand-owned media, and any other publisher whose underlying business is selling a product or service, captures 76% of citations on average, with the per-intent share ranging from 59% (Tutorial) to 89% (Local).
Three observations follow.
It is not a concentration effect, it is a long-tail effect. The AI does not lean on a hard core of a few dozen authoritative publishers. It draws from a wide spread of corporate editorial content, the majority of which appears only once or twice across the dataset. This inverts the SEO playbook of the past decade: it isn't a handful of "hub" pages capturing the bulk of the signal, it is a broad editorial production declined by intent and topic.
The classical authority signals are quietly receding. In traditional SEO, Wikipedia, established press, and institutional sites carried the bulk of the authority signal. In our measurements, Wikipedia represents only 0.2% to 2.7% of citations depending on intent. Press media (economic, tech, mainstream) cap at 1% to 2% on every intent type. The encyclopedic and journalistic references that organized fifteen years of SEO discourse have become marginal in French AI answers.
The brand has become its own primary authority source. This is not a metaphor. When the AI answers in French, three out of four citations come from publishers whose underlying business is the topic at hand. A brand's content strategy is no longer one acquisition channel among others, it is its representation channel in the AI layer. Editorial silence is no longer a missed opportunity, it is a structural invisibility. This is the headline. The rest of the paper unpacks how the source mix shifts by intent (Parts 3-4), how a single change in question framing reshapes everything (Part 5), how the two assistants diverge in their retrieval personalities (Part 6), and what GEO teams should actually do about it (Part 7).
150 French prompts, all written by us, fully unbranded (no specific brand mentioned in any prompt)
9 intent typologies: Definition / education, Tutorial / how-to, Open recommendation, Comparison & alternatives, Reliability / reputation, Problems & troubleshooting, Pricing & commercial terms, Legal / compliance / security, Local / proximity
15 prompts per intent, with the Reliability intent split into two sub-batches: 15 neutrally-framed prompts and 15 negatively-framed prompts (rephrasings such as "why is X criticized", "worst flaws of Y") to test the framing effect at constant intent
2 providers: ChatGPT (Core) and Perplexity
2 runs per prompt per provider (4 cumulative answers per prompt)
600 generated answers, of which 430 are retained after the no-citation filter (see below)
4,171 citations issued across 1,819 unique domains
Language French, country inference France, no auto-detect competitor (focus on sources)
To evaluate the sourcing profile, what the AI mobilizes when it mobilizes anything, we exclude all answers that contain zero citations. The binary "search or no-search" decision is informative but distinct, and mixing it into the family-share metric would conflate two phenomena. After filtering, the analysis is performed on 430 answers: all 300 Perplexity answers (Perplexity cites in 100% of cases by design) and 130 ChatGPT answers out of 300.
We classified each cited domain into one of nine generic families. The taxonomy is opportunistic, not theoretical, and the brand-owned bucket is deliberately broad.
.gouv.fr portals, regulators (CNIL, ARCEP, ACPR, AMF), professional orders (Notaires de France, Ordre des experts-comptables), European institutions, public agencies (Bpifrance, France Num)This bucket-9 catch-all is itself an observation. There is no universally accepted classification of "AI source types" in French, and every GEO team will need to build a workspace-specific taxonomy. Productizing this classification work (per-workspace source tagging) is on the Qwairy product roadmap and is partly motivated by this study.
These are detailed in Part 9. The headline limitations are: 9-intent grid (not exhaustive), 15-30 prompts per cell (margin of error around ±10 points), 2-provider scope, 4 cumulative runs (snapshot), French only, manual classification of domains (subjective), and snapshot period (model versions evolve).
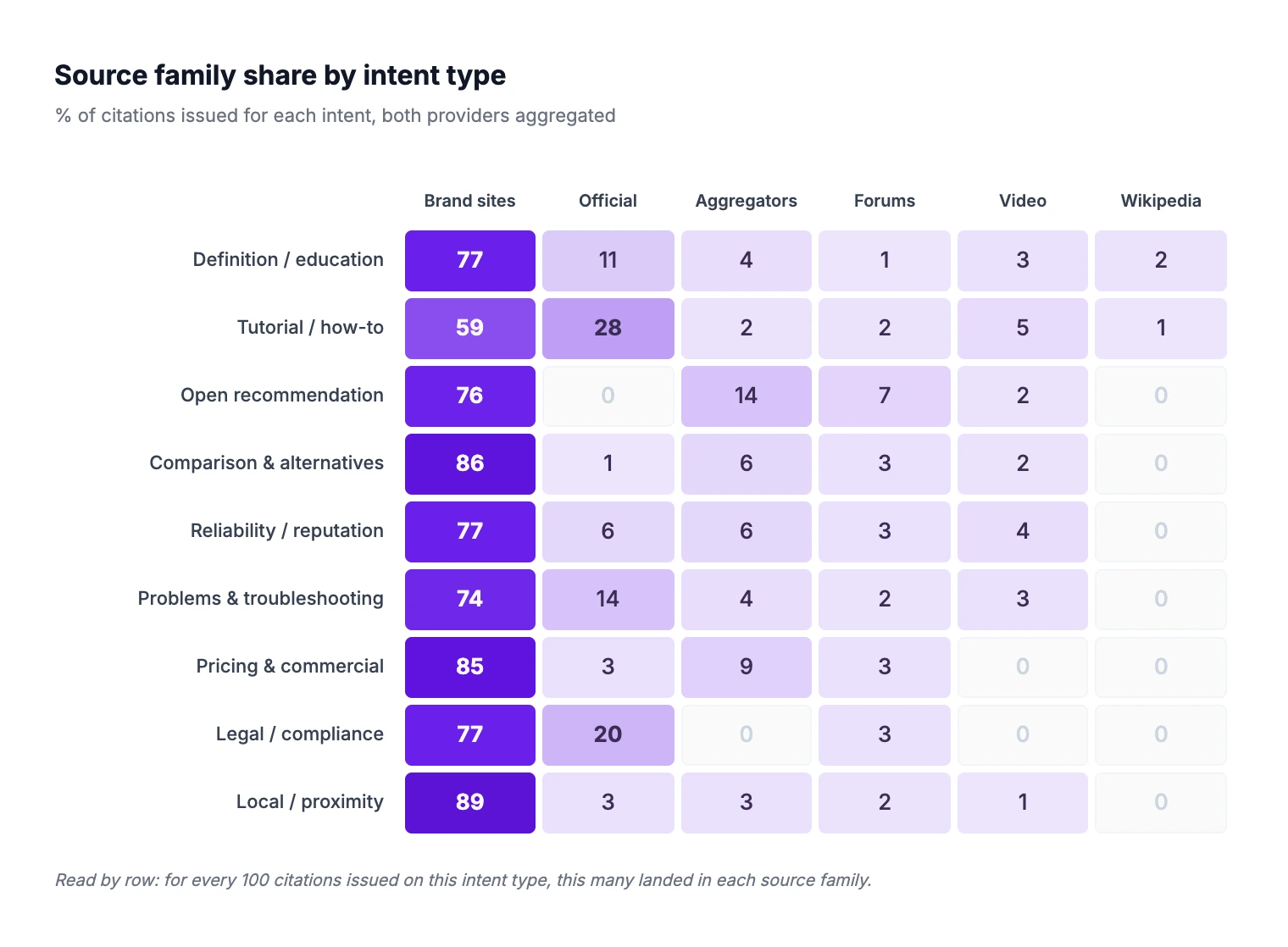
The matrix below reads by row: out of 100 citations issued for that intent's prompts, X% belong to a given family. Both providers are aggregated.
Intent | Brand/SEO | Official | Aggreg. | Forums | Video | Wikipedia |
Definition / education | 77 | 11 | 4 | 1 | 3 | 2 |
Tutorial / how-to |
 Three patterns emerge.
Three patterns emerge.
Normative-frame questions summon official sources. Tutorial (28%) and Legal (20%) pull four to five times more citations from .gouv.fr and institutional sites than the study average. When a user asks "how to create a SASU" or "what are the GDPR obligations for an e-commerce site", the AI leans heavily on the Service Public and CNIL portals. For brands operating in regulated sectors, being referenced by an institutional actor is no longer an editorial nice-to-have, it has become a condition of presence in the AI's answer.
Aggregators and forums emerge on commercial recommendation, and only there. Open recommendation is the only intent where aggregators (14%) and forums (7%) jointly cross 20% of citations. On every other intent type, both families remain in single digits or absent. The "top X" content format and the community-forum format keep a specific, well-bounded GEO utility, exactly on the queries where users are picking between options.
Comparison and Local are pure brand-editorial territory. At 86% and 89% respectively, these two intents are nearly mono-family. The AI almost exclusively pulls from brand-owned editorial when answering comparison questions or local-search prompts. Wikipedia, press, and institutional sources are essentially absent from those answers. A brand that wants to be cited on comparison or local intent has no fallback: its own editorial corpus is the only path.
Run a free audit: see if ChatGPT, Gemini and Copilot recommend you, in about a minute.
To ground the matrix in concrete behavior, here are three prompts from our dataset, each asked to both assistants, with the actual citation profile each AI produced. Sources are described by family and category to keep specific commercial publishers anonymous.
This is a textbook administrative tutorial prompt. Both assistants source it heavily, and both reach for official portals first.
ChatGPT pulled its top citations from impots.gouv.fr (12 citations on this single prompt), arcep.fr (8), and the Google results page (6). Heavy institutional sourcing, almost no brand-owned content on top positions.
Perplexity went broader, with youtube.com (12 citations) leading, followed by service-public.gouv.fr (7), bpifrance-creation.fr (6), and a long tail of legal-services editorial publishers.
What to notice. On a question with a strong institutional answer, ChatGPT concentrates citations on a few .gouv.fr portals. Perplexity diversifies into video and corporate editorial publishers in the legal-services vertical. Same prompt, two very different source experiences.
A commercial recommendation prompt with no brand mentioned. The mix shifts dramatically.
ChatGPT placed reddit.com as its top source (14 citations on this single prompt), followed by a banking comparator and a B2B accounting platform. Reddit dominates the citation profile, accounting for nearly half of all sources cited on this prompt.
Perplexity went without forums entirely. Its top sources were two commercial editorial publishers (one positioning as a B2B SaaS comparison hub, one as a digital-transformation media) and youtube.com.
What to notice. Recommendation queries are the outlier where forum content cracks the citation profile. ChatGPT made Reddit a primary source. Perplexity, on the same prompt, ignored forums and pulled exclusively from commercial publishers. A brand competing on recommendation queries needs both a strong Reddit-community presence (for the ChatGPT exposure) and a strong third-party editorial presence (for the Perplexity exposure). One asset rarely covers both.
Same Reliability intent as a neutral question would be, but rephrased in critical register.
ChatGPT mixed reddit.com (high share), a consumer-finance editorial publisher, and a few independent personal-finance blogs.
Perplexity pulled from a mix of consumer-finance editorial publishers, a few news media articles on previous crowdfunding incidents, and YouTube reviews. Zero institutional sources, despite the AMF (the French market authority) regulating the sector.
What to notice. No official source appears in either provider's citations on this prompt. The same intent in neutral framing would have pulled amf-france.org and the financial supervisor's portals; the critical framing erased them. Part 5 quantifies this effect across the full negative-framing sub-batch.
On the 15 Reliability prompts rephrased in critical register, the family mix reorganizes dramatically:
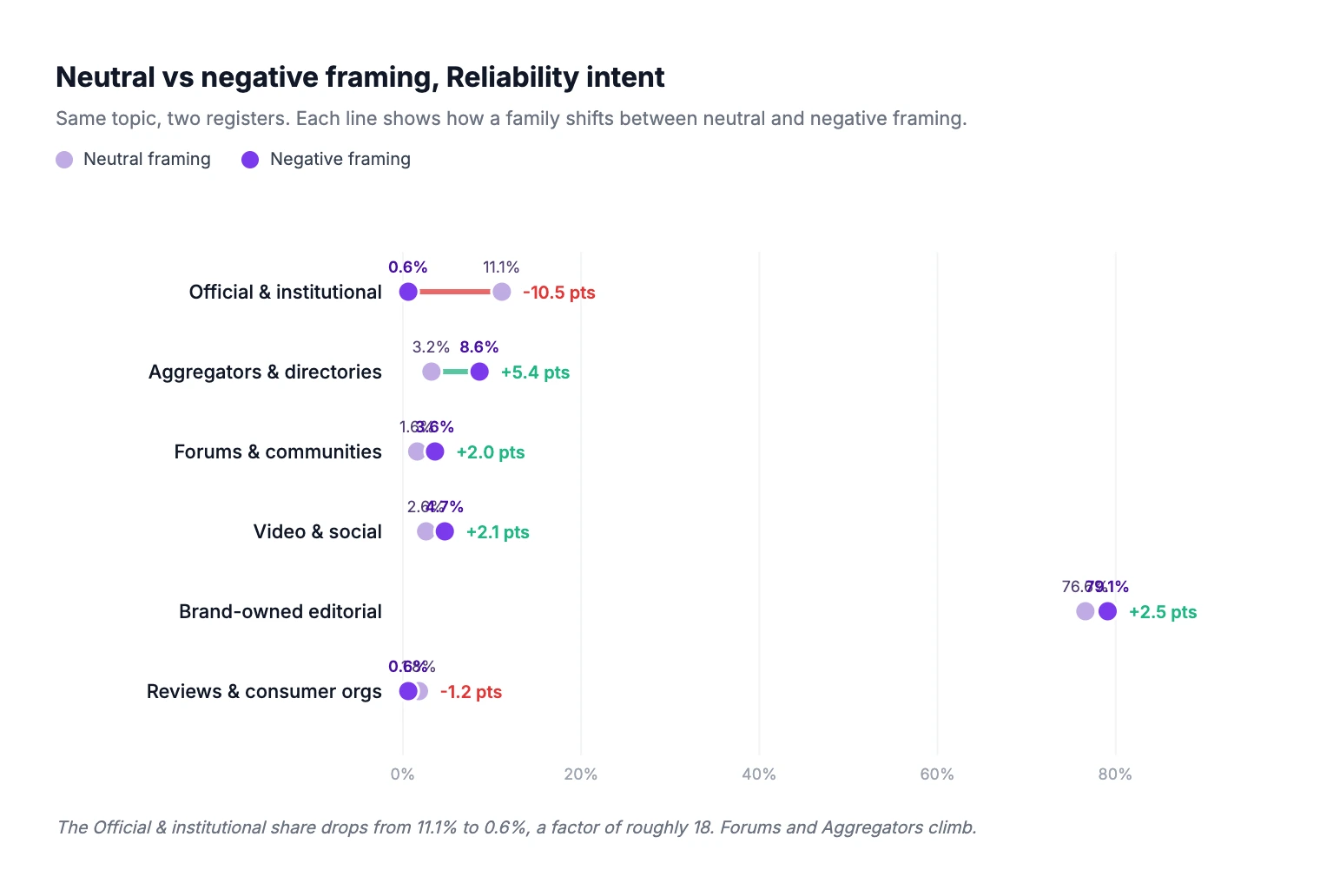 The most striking effect is on official sources: they collapse. At constant intent, rephrasing the question in a critical register makes the institutional share drop by a factor of roughly 18. The model, it seems, does not associate authoritative sources with a register of disapproval. It pivots toward sources where criticism has native legitimacy: aggregators, forums, video.
A more unexpected effect: the share of review platforms and consumer associations also recedes under negative framing. This is counter to the intuition that critical questions would amplify those sources. The likely explanation is that consumer-review platforms produce less structurally critical content than their reputation suggests, much of their published content remains neutral or editorially moderated.
The most striking effect is on official sources: they collapse. At constant intent, rephrasing the question in a critical register makes the institutional share drop by a factor of roughly 18. The model, it seems, does not associate authoritative sources with a register of disapproval. It pivots toward sources where criticism has native legitimacy: aggregators, forums, video.
A more unexpected effect: the share of review platforms and consumer associations also recedes under negative framing. This is counter to the intuition that critical questions would amplify those sources. The likely explanation is that consumer-review platforms produce less structurally critical content than their reputation suggests, much of their published content remains neutral or editorially moderated.
The tactical implication is that there are two distinct source landscapes for the same theme. A "positive/neutral" landscape and a "negative/critical" landscape. A brand seeking to control what is said about it in AI answers must work both registers. A GEO strategy that only addresses positive framing cedes 100% of the critical conversation to other actors. This is a point rarely addressed in existing GEO playbooks, and for brands with reputation stakes, it is a structural risk. The negative framing was tested on only one intent (Reliability) and one axis (positive vs negative). Extrapolating the ×18 magnitude to other intent types would be premature. But the direction of the effect (official sources retreat from critical registers) is consistent across every individual prompt in the sub-batch.
At comparable scope (sourced answers only), both assistants cite a similar number of domains per answer: roughly 8 citations on average for ChatGPT and 10 citations for Perplexity. The volume of cited information sits in the same order of magnitude. It is on the composition of that information that the two assistants diverge sharply:
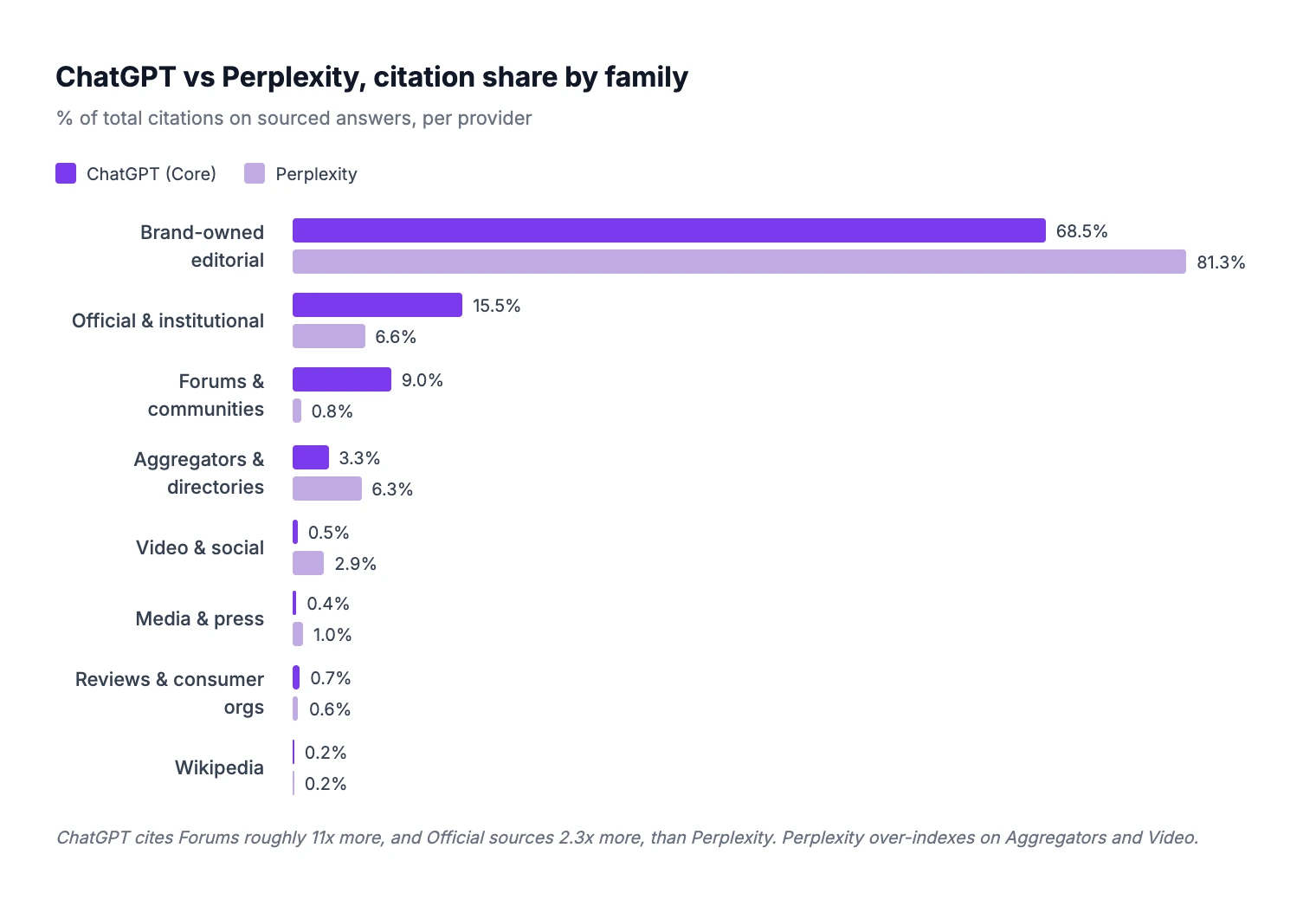 Three differentials stand out:
Three differentials stand out:
ChatGPT cites roughly 11× more forum content than Perplexity (9% vs 0.8%). When ChatGPT chooses to source, it leans heavily into community discussions, particularly on recommendation prompts. Perplexity essentially does not use forums.
ChatGPT cites roughly 2.3× more institutional sources (15.5% vs 6.6%). Its retrieval gives meaningfully more weight to .gouv.fr and regulator portals when it does source.
Perplexity cites roughly 6× more video and social content (2.9% vs 0.5%) and pulls more aggregators (6.3% vs 3.3%). It also concentrates more heavily in the brand-editorial bucket (+12.8 points vs ChatGPT).
These gaps suggest that both assistants implement qualitatively different retrieval strategies, with different weightings of source families. We cannot confirm the underlying mechanism from outside the systems: it may be a different web-search index, different reranking heuristics, or different policy filters during synthesis. What we can confirm is that the gaps are consistent across every intent type we tested. The strategic consequence is that improving your brand visibility on Perplexity and improving it on ChatGPT are two distinct projects, with overlapping but non-identical asset stacks. Optimizing only for one of them leaves the other under-covered.
The matrix in Part 3 is the actionable artifact of this study. Below, we translate it into per-intent recommendations. The logic is consistent: identify the dominant source family for the intents your brand cares about, then invest disproportionately in producing or being referenced by content of that family.
See your mentions across ChatGPT, Claude and Perplexity in real time, the moment buyers ask.
Co-publish with institutional actors when applicable. Professional associations, regulators, or public agencies that publish how-to content in your domain are direct paths to AI citations.
Structured how-to schema, step-by-step on your own editorial pages.
Produce video tutorials. YouTube is one of the only intents where video citations cross 5%, on Perplexity especially.
Active Reddit France presence. Recommendation queries are the only intent where forum content reliably surfaces. Subreddit moderation work, contextual mentions, and AMAs are direct GEO actions.
Inclusion in third-party aggregators / comparators. Even commercial comparators with weaker journalistic standards carry meaningful citation share on this intent.
Own brand editorial on "best X" pages, with concrete differentiators, real numbers, customer profiles.
Own your X vs Y and alternatives to X pages. The AI cites brand-owned editorial almost exclusively for this intent. Your own corpus is the most direct lever.
Cover every meaningful comparator your prospects mention, not only your direct competitors.
Refresh comparison content every quarter, with year-tagged updates.
Reference and align with .gouv.fr and regulator portals. Cite them in your own content; link to them; co-author when possible.
Co-publication with professional associations is unusually high-leverage here, given the brand-owned editorial bucket also includes consulting and legal-services publishers.
Structured FAQ on compliance-adjacent questions, with explicit regulatory references.
Transparent pricing pages. The AI cites brand-owned pricing content massively when it can find it.
Inclusion in vertical pricing aggregators, particularly the niche ones: they carry surprising citation weight.
Local landing pages, one per geographic market.
Local directories and Google Business keep their structural role, but the bulk of citations still flows through brand-owned editorial.
Canonical explainers on your own site, with structured definitions.
Wikipedia presence stays marginal but still non-zero. Co-editing relevant Wikipedia pages remains a low-effort, low-priority lever.
Reality: in French AI answers, Wikipedia tops out at 2.7% on its best intent, and major press caps at 2%. The authority signal has shifted to brand-owned editorial publishers. Editorial silence is now a structural visibility risk.
Reality: ChatGPT and Perplexity cite different families in different proportions. ChatGPT favors institutional sources and Reddit. Perplexity favors aggregators and video. A brand visible on one is not automatically visible on the other.
Reality: on commercial recommendation prompts, forums (Reddit) are the second-largest cited family after brand-owned editorial. Ignoring Reddit on the recommendation intent is a measurable visibility loss.
Reality: the source landscape for "why is X criticized" is structurally different from the source landscape for "what is X". Institutional sources collapse; forums and aggregators rise. Your positive-content investment does not carry over to the negative-framing landscape.
Reality: the family mix shifts by 80+ points between intents. A legal prompt pulls 20% institutional and 0% aggregator; a recommendation prompt pulls 0% institutional and 14% aggregator. GEO strategy needs intent-level segmentation, not a single global playbook.
Sample size. With 15-30 prompts per intent and 4 cumulative runs, the statistical margin on any matrix cell sits around ±10 points. Orders of magnitude hold. Fine 1-2 point comparisons within a cell do not.
Temporal snapshot. Both assistants push regular model updates, and retrieval pipelines evolve. A measurement repeated at T+3 months can meaningfully diverge. The cyclical format is designed for this: Q3 2026 will produce a comparable snapshot.
Provider scope. Two providers only. Gemini, Claude, Mistral, and DeepSeek are out of scope for this iteration, due to incomplete instrumentation in our internal stable pipeline. We expect Gemini and Claude to be in scope for Q3.
Linguistic scope. French only. Reddit, Wikipedia, and press-media share are known to differ markedly in anglophone markets. Reddit, in particular, weighs much more heavily on English-language AI answers.
Source taxonomy. Nine families is convenient and opportunistic. The brand-owned bucket alone blends SaaS publishers, professional services firms, corporate blogs, and brand-owned media (objects with very different GEO implications). Decomposing this bucket into sub-families is the most pressing improvement for v2, and it is partly motivated by client feedback.
Framing axis. Tested on one intent (Reliability) only. The ×18 magnitude on official sources should not be extrapolated to other intents without dedicated testing.
Branded vs unbranded. We worked exclusively in unbranded mode. The effect of introducing a brand name into the prompt (branded vs unbranded at constant intent) is a known GEO question we did not address in this iteration.
Subdivide the brand-owned bucket into SaaS publishers, professional services firms, corporate editorial blogs, and vertical platforms
Add Gemini and Claude to the provider scope (instrumentation work in flight)
Densify the sample to 25-30 prompts per intent, reducing margin of error
Test branded vs unbranded at constant intent on 2-3 representative intents
Measure source rotation across runs for the same prompt at T+2 weeks
Cross-reference with search volume to weight intents by business importance
If Q3 2025 asked "which AI platform should I optimize for?" and Q1 2026 asked "which fan-out playbook fits my market?", Q2 2026 asks "which source families dominate the queries I care about, and am I present in them?" The three lines to internalize:
The Q3 2026 iteration will refine the brand-owned bucket, add Gemini and Claude, and test the branded vs unbranded axis. We expect at least one of these refinements to materially update the playbook.
Conducted by: Nicolas Ilhé (Qwairy)
Dataset: 150 French unbranded prompts across 9 intent typologies, run twice each on ChatGPT (Core) and Perplexity in Q2 2026. 600 generated answers, 430 retained after the no-citation filter, 4,171 citations across 1,819 unique domains. Brand monitoring conducted in a dedicated research workspace on the Qwairy platform; no client data was used in this study.
Methodology: Qualitative analysis of source family composition by intent type and by provider. Domains classified manually into nine generic families. Per-cell percentages computed on the total citations for the relevant slice. Negative-framing comparison performed on a 15-prompt sub-batch at constant intent (Reliability). Statistical margins of error around ±10 points per cell at n = 15-30 prompts.
The "brand-owned editorial & SEO publishers" bucket is deliberately broad and mixes objects of different GEO natures. This is a methodological compromise for v1; subdivision is the priority improvement for the next iteration.
Source classification is manual and inherently subjective on borderline domains (e.g., a corporate editorial blog vs an editorial publisher with multiple revenue streams). The matrix is robust to small reclassifications, but any single cell at 2-3 percentage points should be read directionally.
We did not name specific commercial publishers in the prompt-example sections (Part 4) to keep the publication competitively neutral. Internal versions of this report include the raw top-source data per intent and per provider.
Prior cyclical research: 184,128-query LLM study (Q3 2025), Query Fan-Out Study Q1 2026
Companion playbook: GEO strategies by platform: ChatGPT, Perplexity, Claude, Gemini
Foundational concept: What is GEO?
Want per-intent citation tracking for your brand? Qwairy monitors brand citations across ChatGPT, Perplexity, Claude, Gemini and expanding providers, with per-source classification and per-intent analytics.
Track your mentions across ChatGPT, Claude, Perplexity and all major AI platforms. Join 1,500+ brands monitoring their AI presence in real-time.
Free trial • No credit card required • Complete platform access
28 |
2 |
2 |
5 |
1 |
Open recommendation | 76 | 0 | 14 | 7 | 2 | 0 |
Comparison & alternatives | 86 | 1 | 6 | 3 | 2 | 0 |
Reliability / reputation | 77 | 6 | 6 | 3 | 4 | 0 |
Problems & troubleshooting | 74 | 14 | 4 | 2 | 3 | 0 |
Pricing & commercial terms | 85 | 3 | 9 | 3 | 0 | 0 |
Legal / compliance | 77 | 20 | 0 | 3 | 0 | 0 |
Local / proximity | 89 | 3 | 3 | 2 | 1 | 0 |
Family | Neutral framing | Negative framing | Change |
Official & institutional | 11.1% | 0.6% | divided by ~18 |
Aggregators & directories | 3.2% | 8.6% | × 2.7 |
Forums & communities | 1.6% | 3.6% | × 2.3 |
Video & social | 2.6% | 4.7% | × 1.8 |
Brand-owned editorial & SEO | 76.6% | 79.1% | stable |
Reviews & consumer organizations | 1.8% | 0.6% | divided by 3 |
Family | ChatGPT (Core) | Perplexity |
Brand-owned editorial & SEO | 68.5% | 81.3% |
Official & institutional | 15.5% | 6.6% |
Forums & communities | 9.0% | 0.8% |
Aggregators & directories | 3.3% | 6.3% |
Video & social | 0.5% | 2.9% |
Media & press | 0.4% | 1.0% |
Reviews & consumer orgs | 0.7% | 0.6% |
Wikipedia | 0.2% | 0.2% |